利用 Grafana Loki 高效收集與監控爬蟲日誌
· 30min
在 Lawsnote 服務期間,因應產品與專案需求,我們需要開發數百支網頁抓取程式 (Web Scraper) 與網頁爬取程式 (Web Crawler),從政府主管機關的網站中擷取特定法學資料,並在資料梳理的同時,進行結構化處理並寫入資料庫中。
網頁抓取程式 (Web Scraper) 與網頁爬取程式 (Web Crawler),以下統稱為 crawlers。
Lawsnote 提供的 Lawsnote Search (法學搜尋引擎)、企業法遵系統方案、Lawsnote Monta (法遵解決方案) 等服務,皆高度講求資料的 即時性 與 準確性。
因此在我們的團隊中,除了例行性的程式開發外,也必須有效率地管理這數百支 crawlers。當任何一支程式發生錯誤時,能夠即時通知相關人員並迅速定位問題,便是我們維運流程中的關鍵。
為了達成這個目標,crawler 的日誌 (Logs) 便需要被妥善地收集與監控。這些日誌不僅包含執行狀態,也涵蓋整個過程中所爬取的請求 URL、HTTP 狀態碼、錯誤訊息 (Error Message) 等重要資訊。
在這篇文章中,我們將介紹如何利用 Grafana Loki 收集與監控這些日誌資料,並最終透過 Grafana 進行可視化展示,打造一個高效、穩定且實用的日誌監控方案。無論你是第一次接觸 Loki,或是想優化排程程式的日誌管理流程,希望這篇文章都能帶來一些實用的參考。
本文架構
這篇文章將從實務出發,介紹如何在 crawlers 專案中導入 Loki 與 Grafana,實作一套好用的日誌監控方案。主要內容包含:
-
為什麼需要日誌監控? - Jump
描述 crawlers 的管理挑戰,以及 logs 在即時監控與錯誤追蹤中的重要性。
-
設計日誌內容 - Jump
介紹日誌的設計原則,包括日誌等級、可結構化日誌設計原則,以及如何判斷哪些日誌值得記錄。
-
使用 Grafana Loki 收集日誌資料 - Jump
包含 Loki、Promtail 安裝與設定,如何將 crawler logs 傳送進 Loki。
-
透過 Grafana 可視化監控日誌 - Jump
如何建立 dashboard、撰寫 LogQL 查詢,以及設定告警通知機制。
-
應用實例 - Jump
實際案例分享與一些擴充應用的建議。
為什麼需要日誌監控?
當系統規模尚小、程式數量不多時,偵錯階段通常可以靠 標準輸出 (stdout) 和 標準錯誤輸出 (stderr) 直接在 terminal 或 console 上查看,抑或是將 log 輸出至檔案中。
倘若規模逐步擴大後,若採用相同方式進行管理,將會面臨以下幾個挑戰:
-
日誌分散於不同主機或容器中,難以集中查閱
當程式數量一多,可能又分散執行在不同機器上,若沒有集中式的日誌收集機制,維運人員往往需要 SSH 到不同機器節點去翻找 log,不僅耗時,也容易遺漏資訊。
-
缺乏統一查詢介面與格式標準,難以追溯問題源頭
每支程式可能使用不同的 log 格式與層級,導致即使 log 都存在,也難以快速篩選出錯誤來源或還原事件順序。
-
日誌儲存空間有限,歷史紀錄易被覆蓋
若未搭配 日誌輪替 (log rotation) 機制,過舊的日誌可能會被覆蓋,導致事後調查時無法取得完整資訊。
-
錯誤發生無法即時通知相關人員
傳統 log 記錄方式僅作為事後檢查之用,不易即時反饋問題。
-
難以進行統計與視覺化分析
若想瞭解各程式的整體執行狀況,以 crawler 舉例有 階段成功和失敗資訊、最常失敗的目標網站、HTTP 狀態碼分布 等,將需自行撰寫腳本分析散落的 log,成效不彰。
什麼樣的資料適合收集?
在設計日誌系統時,並不是所有輸出都適合或需要被收集。我們應該根據系統特性與實際需求,挑選對後續除錯、分析與監控有實質幫助的資料。以開發 crawlers 的經驗來說,建議可以優先考慮以下幾類資訊:
-
請求相關資訊
包括 目標 URL、HTTP method、status code、response time 等,能協助判斷目標網站是否正常、回應速度是否合理。
2025-01-01 12:00:00 - Requesting URL: https://example.com/api/data 2025-01-01 12:00:01 - Response Status Code: 200 2025-01-01 12:00:01 - Response Time: 200ms -
任務執行階段狀態
每個任務的開始與結束時間,以及中間執行的步驟 (如:下載 → 解析 → 寫入資料庫) 等,有助於還原執行流程與評估效能瓶頸。
2025-01-01 12:00:00 - Task started: Fetching data from example.com 2025-01-01 12:00:01 - Parsing data... 2025-01-01 12:00:02 - Writing data to database... 2025-01-01 12:00:03 - Task completed: Data successfully fetched and stored. -
錯誤與異常
包括 HTTP 錯誤、timeout、資料解析失敗 等。這類訊息應清楚標示,方便集中查詢與設計告警條件。
2025-01-01 12:00:00 - HTTP Error: 404 Not Found 2025-01-01 12:00:00 - Timeout Error: Request to https://example.com/api/data timed out. 2025-01-01 12:00:00 - Parsing Error: Failed to parse JSON response from https://example.com/api/data -
環境、版本與其他自定義資訊
包括 爬蟲版本、執行機器節點 IP、執行時間的環境變數、使用的函式庫版本 等,有助於 debug 與還原特定部署狀態。
2025-01-01 12:00:00 - Crawler Version: 1.0.0 2025-01-01 12:00:00 - Hostname: crawler-node-01 2025-01-01 12:00:00 - IP Address: 10.0.0.15 2025-01-01 12:00:00 - Node.js Version: v22.11.0 2025-01-01 12:00:00 - Environment: production 2025-01-01 12:00:00 - Dependencies: axios@1.6.8, cheerio@1.0.0-rc.12
設計日誌內容
撰寫日誌並不是單純的 console.log("我到了這一行") 就好。良好的日誌設計,應同時考量 除錯效率、可視化需求 以及 機器可讀性 等面向。
日誌中若參雜的一般、重要和錯誤資訊,以人工檢視相當沒有效率。
設想一個情境:某支 crawler 程式在生產環境中執行,產生了數萬行日誌,過程看似順利,卻最終未能正確將資料寫入資料庫。
這時我們得回頭查看日誌來定位問題。但若資訊過於雜亂、缺乏層次分類,即使錯誤訊息已經出現,也可能輕易被掩埋其中。
例如以下這段輸出:
2025-01-01 12:00:00 - Starting task: fetch law data from site A
2025-01-01 12:00:01 - Target URL: https://example.com/api/data
2025-01-01 12:00:02 - Status Code: 200
2025-01-01 12:00:03 - Response time is high: 1200ms
2025-01-01 12:00:04 - Failed to parse response JSON乍看之下每一行都像一般資訊,但其實最後一行才是造成資料缺失的主因。如果沒有良好的等級分類或結構化方式,要靠人工逐行排查才能找出線索,不但效率低,也容易誤判。
這也說明了:
日誌的設計品質,將直接影響開發者在緊急狀況下的反應速度與問題定位能力。
因此,在後續章節中,我們將會探討:
- 如何為日誌資訊設計合理的 等級分類
- 哪些類型的資訊值得被記錄下來
- 為何「可結構化日誌格式」對於查詢與監控至關重要
日誌等級
除了決定「記錄什麼」,另一個關鍵是「以什麼等級記錄」。合理區分 log 等級,不僅有協助後續查詢與視覺化統計,也能減少不必要的雜訊干擾。
以下是常見的 log 等級分類及其適用情境:
-
debug— 除錯時用的詳細資訊,例如變數值、執行流程細節。適合開發環境使用,通常在正式環境會關閉或降低權重。
-
info— 系統正常執行的重要節點,例如任務啟動、請求成功、資料寫入完成等。是大多數 log 的主體,可用於觀察系統整體運作狀態。
-
warn— 非預期但尚可接受的狀況,例如重試、資料格式不符但能容錯處理。通常代表潛在異常或需要注意的現象。
-
error— 發生錯誤且可能影響任務執行的情況,例如 HTTP 失敗、解析錯誤、寫入失敗等。應列為重點監控對象,並視情況觸發告警機制。
-
fatal或critical— 系統無法繼續執行的嚴重錯誤,會中斷整個流程。可視為需立即介入的事件 (有些 logger 可設定觸發終止程序)。
程序前一小節的範例,加上了日誌等級後,會變成:
2025-01-01 12:00:00 - INFO - Starting task: fetch law data from site A
2025-01-01 12:00:01 - INFO - Target URL: https://example.com/api/data
2025-01-01 12:00:02 - INFO - Status Code: 200
2025-01-01 12:00:03 - WARN - Response time is high: 1200ms
2025-01-01 12:00:04 - ERROR - Failed to parse response JSON良好的 log 設計不僅在於資訊完整,更在於資訊有層次。建議根據情境合理設定 log 等級,並搭配集中式日誌系統進行過濾、查詢與告警設定,以提升整體維運效率。
如何判斷「哪些日誌值得記錄」?
除了 log 等級的設定之外,另一個常見問題是:「哪些 log 值得記錄下來?」根據前述章節的討論,我們可以歸納出幾個通用原則,協助你判斷哪些日誌資訊具有實際價值,應納入紀錄與監控範圍:
-
可用於判斷系統是否「有在運作」
包含任務的開始、結束、請求是否成功等,這些都是觀察系統狀態的基礎資訊。這類訊息適合設為
info等級,作為系統流程的日常紀錄依據。 -
可用於觀察效能瓶頸或趨勢
例如 response time、任務執行時間等,可以透過 log 分析出哪個階段最耗時,協助做後續優化。這類資料也屬於
info等級,對於後續視覺化有所幫助。 -
可用於追蹤錯誤的發生條件與上下文
記錄錯誤類型、來源 URL、發生時間與當下的資料,有助於快速定位與還原問題。這類資訊應設為
error或warn等級,並可搭配告警條件使用。 -
可用於重建問題發生時的執行環境
版本號、主機 IP、環境變數、相依套件版本等部署細節,能協助重現 bug 發生時的環境狀態。建議於啟動階段以
info等級記錄一次即可。
這些原則不只適用於 crawler 系統,同樣也適用於排程任務 (cron jobs)、API server、資料處理流程 (如 ETL) 等場景,都是建立健全日誌系統時可參考的設計依據。
可結構化的日誌設計原則
當你需要快速回答「哪一支爬蟲最常出錯?」或「哪個網址平均訪問最慢?」等類似問題時,扁平化的文字 log 幾乎無法幫上忙,而結構化的 log 則能輕鬆達成。
在 JavaScript 或 Node.js 實務中,雖然 console.log() 是最簡單快速的輸出方式,但若希望日誌能被機器判讀、具備良好的過濾條件與分析能力,「可結構化」就變得相當重要。
所謂 可結構化日誌 (Structured Logging),是指使用具明確欄位命名的格式 (最常見為 JSON) 輸出 log。這樣的做法能讓日誌系統 (如 Loki) 更容易針對欄位進行搜尋與 聚合 (Aggregation),有助於提升查詢效率、視覺化呈現能力,以及與告警系統的整合性。
例如,若我們在爬取資料過程中發生了解析 JSON 錯誤,傳統的 log 記錄方式可能會是:
2025-01-01 12:00:04 - ERROR - Failed to parse response JSON以 JSON-based 的格式呈現,會變成:
{ "timestamp": "2025-01-01T12:00:04.000Z", "level": "error", "message": "Failed to parse response JSON" }為了方便解說,將 JSON 的排版稍作優化:
{
"timestamp": "2025-01-01T12:00:04.000Z", // 時間戳記,通常以國際標準 ISO 8601 格式或 UNIX epoch 表示,方便後續查詢與排序。
"level": "error", // 日誌等級,例如 info、warn、error,用來快速分類與過濾。
"message": "Failed to parse response JSON" // 實際的訊息內容,可搭配 error stack 或說明文字。
}根據實務場景,可以嘗試加入更多欄位,將有助於支援更細緻的分析:
{
"timestamp": "2025-01-01T12:00:04.000Z",
"level": "error",
"message": "Failed to parse response JSON",
"url": "https://example.com/api/data", // 發生錯誤的請求網址,有助於追蹤特定目標來源。
"statusCode": 200, // HTTP 狀態碼,即使非 5xx 錯誤也可作為失敗判斷依據。
"durationMs": 1200, // 請求耗時,便於觀察效能瓶頸與超時風險。
"crawlerId": "law-fetcher-a", // 爬蟲任務的識別代號,可對多任務進行分類。
"env": "production", // 環境資訊,例如 production、staging、dev。
"hostname": "crawler-node-01" // 實際執行任務的主機名稱,利於還原部署情境。
}在後續章節中,我們將說明如何透過 Grafana Loki 解析這些欄位,並使用 LogQL 進行快速查詢與視覺化展示。
使用 Grafana Loki 收集日誌資料
在前一章中,我們說明了如何設計一份良好的爬蟲日誌。本章將實作一套本地端日誌收集環境,透過 Docker Compose 建立最小可行架構,內容包含:
- 日誌收集器 Promtail
- 儲存後端 Loki
- 可視化工具 Grafana
- 模擬產生日誌的 Node.js 應用程式
這份環境設定適合用於本地測試與學習,並能作為日後部署正式監控環境的基礎。
角色介紹與環境建置
在以 Loki 為日誌系統的架構中,主要由三個元件各司其職,分別負責日誌的收集、儲存與可視化:
| 元件 | 角色 | 功能描述 |
|---|---|---|
| Promtail | 日誌收集器 | 日誌資料的收集與傳送工具,常見用法是從檔案或容器 stdout/stderr 中擷取 log,轉送至 Loki。也支援透過標籤自動分類。 |
| Loki | 日誌儲存庫 | 日誌資料的儲存與查詢系統,負責接收、儲存與提供查詢介面。適合用來處理結構化或半結構化的 log 資料。 |
| Grafana | 可視化介面 | 日誌資料的可視化與監控工具,負責提供 使用者介面 (UI),讓使用者能夠查詢、分析與視覺化日誌資料。 |
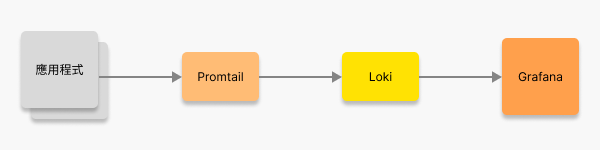
構築 Loki 日誌系統的流程
我們將使用 Docker Compose 建立最小可行的 Grafana Loki 環境,從零開始撰寫 docker-compose.yaml 配置檔。
撰寫 docker-compose.yaml 的起手式
接下來,我們會建立一份名為 docker-compose.yaml 的檔案,並在其中定義四個服務:Loki、Promtail、Grafana 與 Node.js 應用程式。
version: '3.8'
networks:
loki:
services:
node-app: # 參見【建立應用程式並輸出日誌】小結
loki: # 參見【設定 Loki】小結
promtail: # 參見【設定 Promtail】小結
grafana: # 參見下一章【透過 Grafana 可視化監控日誌】完整 source code: docker-compose.yaml
建立應用程式並輸出日誌
這個段落會建立一支模擬 crawler 的 Node.js 應用程式,並透過 pino 將 log 以結構化格式輸出到 stdout。
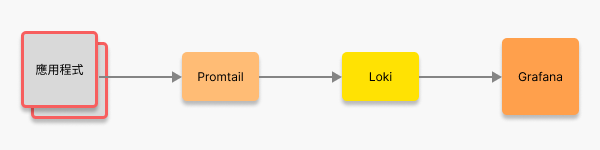
於應用程式階段輸出相應的 logs
node-app 的 Docker Compose 設定
我們需要建立一個 Node.js 應用程式,並將其容器化為 node-app service。docker-compose.yaml 細節的設定如下:
services:
node-app:
build: ./app
container_name: node-app
labels:
job: node-app
restart: always
networks:
- loki
labels.job設定將成為後續 log 的來源標籤 (label),Loki 可用來依據 job 過濾 log 資料。
log 輸出行為說明
這支應用程式的行為設計如下:
- 每 5 秒輸出一筆
info級別的 log(模擬一般執行流程) - 每 10 秒輸出一筆
error級別的 log(模擬錯誤情境)
搭配 pino 套件,可輸出符合 Loki 結構化查詢的 JSON log,例如:
{
"level": "info",
"message": "Fetched data successfully",
"timestamp": "2025-01-01T12:00:00.000Z"
}上述欄位中,level 可對應至 log 等級,timestamp 可支援時序查詢與可視化統計,message 則為實際訊息內容。
接下來,我們將介紹如何透過 Promtail 擷取這些 logs 並傳送至 Loki 儲存與分析。
設定 Promtail
接下來我們將完成 Promtail 的服務與設定檔,讓日誌能從 container 被正確收集。
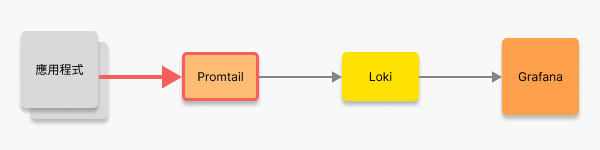
透過 Promtail 接收 logs
promtail service
我們同樣將 config 資料夾掛載到容器中,並指定 Promtail 的設定檔路徑。
另外,也會將 /var/run/docker.sock 掛載到容器中,這是為了讓 Promtail 可以與 host 的 Docker Daemon 溝通,取得正在執行中的容器清單與相關資訊。這樣就能從 container 的 stdout 和 stderr 中擷取 log,搭配後續小節的 promtail-config.yaml 設定檔,即可完成 logs 的收集與傳送。
docker-compose.yaml 細節的設定如下:
services:
promtail:
image: grafana/promtail:3.4.1
volumes:
- /var/run/docker.sock:/var/run/docker.sock # 掛載 Docker socket,讓 Promtail 可以讀取容器資訊
- ./config:/mnt/config # 將 config 資料夾掛載到容器中
command: -config.file=/mnt/config/promtail-config.yaml
networks:
- lokipromtail 設定檔: promtail-config.yaml
接下來,我們需要建立一個名為 promtail-config.yaml 的設定檔,供前述的 promtail service 使用。
這份設定主要針對 Docker container 的 log 擷取,以下為設定內容:
server:
http_listen_port: 9080
grpc_listen_port: 0
positions: # 記錄上次讀取到的日誌位置,避免重複擷取
filename: /tmp/positions.yaml
clients: # 定義要將日誌推送到哪個 Loki instance
- url: http://loki:3100/loki/api/v1/push
scrape_configs:
- job_name: docker
docker_sd_configs: # ①
- host: unix:///var/run/docker.sock
relabel_configs: # ②
- source_labels: [__meta_docker_container_name]
target_label: job
regex: '/(.*)'
replacement: $1scrape_configs 各欄位說明:
docker_sd_configs: 使用 Docker 的 服務發現 (Service Discovery) 機制,來自動獲取正在運行的 containers 資訊。relabel_configs: 重新標籤 (Relabeling) 的設定,這裡我們將抓取到的 container 名稱標籤化為job,方便後續查詢與過濾。
設定 Loki
後續,我們將完成 Loki 的服務與設定檔,讓 Promtail 能夠將日誌傳送至 Loki 儲存。
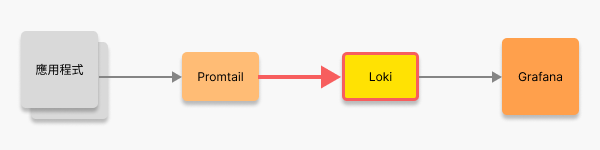
將 Promtail 接受的日誌傳送至 Loki 儲存
loki service
我們將額外的 config 資料夾掛載到容器中,並指定 Loki 的設定檔路徑。
docker-compose.yaml 細節的設定如下:
services:
loki:
image: grafana/loki:3.4.1
ports:
- '3100:3100'
volumes:
- ./config:/mnt/config # 將 config 資料夾掛載到容器中
command: -config.file=/mnt/config/loki-config.yaml
networks:
- lokiloki 設定檔: loki-config.yaml
在 loki service 中提到過,我們需要建立一個名為 loki-config.yaml 的設定檔,以供其使用。以下為設定內容:
auth_enabled: false # 關閉權限驗證
server:
http_listen_port: 3100
common:
path_prefix: /tmp/loki # ①
storage: # ②
filesystem:
chunks_directory: /tmp/loki/chunks
rules_directory: /tmp/loki/rules
replication_factor: 1 # ③
ring: # ④
kvstore:
store: inmemory
schema_config:
configs:
- from: 2025-04-01 # ⑤
store: tsdb # ⑥
object_store: filesystem # ⑦
schema: v13 # ⑧
index: # ⑨
prefix: index_
period: 24hcommon 各欄位說明:
path_prefix: 指定 Loki 儲存資料的根目錄,後續 chunks 與 index 等都會相對於此路徑建立。storage.filesystem: 設定資料實際儲存位置,包括 chunks 與 rules。replication_factor: 設定資料副本數,本地測試使用1即可。ring.kvstore.store: 設定 ring 用來追蹤 instance 狀態的方式,單節點時使用 inmemory 即可,正式環境會使用etcd、consul等外部儲存。
schema_config 各欄位說明:
from: 指定此組 schema 的生效時間。即使只使用一組設定也必須加上,是 Loki 的必要欄位。store: 使用 使用時間序列資料庫 (tsdb) 儲存資料,這是 Loki 的預設儲存方式,並且是撰文當下 Grafana 官方推薦的儲存方案。object_store: 代表將 chunks 儲存在本機檔案系統 (例如/tmp/loki/chunks目錄),適合用於本地測試。正式環境可改為 S3、GCS 等物件儲存方式。schema: 代表使用 Grafana 官方的 schema 版本,以提供更佳的查詢效率與結構。若 schema 有變更版本,可參考最新的官方 period_config。index: 設定索引檔的檔名前綴與生成週期,這裡設為每天產生一份 (24h),前綴為index_。
當中需要留意的是 from 屬性 —— 因為它是 required。
Loki 會根據這個時間點來決定使用哪個 schema 來儲存資料,而這樣的設計讓我們可以在未來的版本中,針對不同的時間範圍使用不同的 schema,來定義出不同的 config 以避免一次性重建所有資料結構。
小結
在這一章中,我們介紹了如何使用 Promtail 和 Loki 來收集、儲存日誌資料。至此,目前的 docker-compose.yaml 配置檔如下:
version: '3.8'
networks:
loki:
services:
loki:
image: grafana/loki:3.4.1
ports:
- "3100:3100"
volumes:
- ./config:/mnt/config # 將 config 資料夾掛載到容器中
command: -config.file=/mnt/config/loki-config.yaml
networks:
- loki
promtail:
image: grafana/promtail:3.4.1
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- ./config:/mnt/config # 將 config 資料夾掛載到容器中
command: -config.file=/mnt/config/promtail-config.yaml
networks:
- loki
grafana:
image: grafana/grafana:10.2.3
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_USER=admin # 將帳號設定為 admin
- GF_SECURITY_ADMIN_PASSWORD=admin # 將密碼設定為 admin
depends_on:
- loki
networks:
- loki
node-app:
build: ./app
container_name: node-app
labels:
job: "node-app"
restart: always
networks:
- loki前節所設定的 promtail-config.yaml 和 loki-config.yaml 將放置於 ./config 資料夾中,並在 compose 期間掛載到容器當中。
docker compose up --build啟動完畢後,後續章節將接續目前的進度,將開始介紹如何在 Grafana 中進行日誌的可視化與監控。
透過 Grafana 可視化監控日誌
我們將延續前一章的內容,使用 Grafana 來可視化與監控 Loki 儲存的日誌資料。本章將說明如何設定 Grafana 與 Loki 的連線,並建立 dashboard 來觀察與分析日誌。內容包含:
- 安裝與啟動 Grafana
- 建立 dashboard 並加入 panel
- 撰寫 LogQL 查詢語言
- 設定 dashboard 告警條件
安裝與啟動 Grafana
Grafana 是一套功能強大的可視化工具,能夠支援多種資料來源 (如 Prometheus、Loki、InfluxDB 等),並透過圖表與查詢語言呈現即時資料狀態。對於 log 系統來說,Grafana 搭配 Loki 不僅能即時查詢文字 log,更能分析 log 結構化欄位、視覺化錯誤分布,甚至設定告警條件,是建構 可觀測性 (Observability) 的重要利器。
grafana service
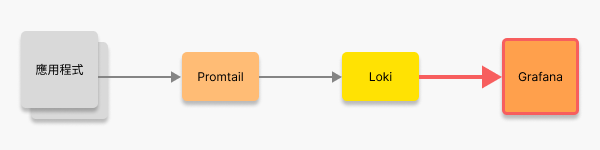
將 Loki 儲存的日誌資料可視化
在 docker-compose 中加入 Grafana 的服務設定,為了方便測試,我們預設帳號與密碼都設為 admin,避免首次登入還需額外設定。
docker-compose.yaml 細節的設定如下:
services:
grafana:
image: grafana/grafana:10.2.3
ports:
- '3000:3000'
environment:
- GF_SECURITY_ADMIN_USER=admin # 將帳號設定為 admin
- GF_SECURITY_ADMIN_PASSWORD=admin # 將密碼設定為 admin
depends_on:
- loki
networks:
- loki啟動與登入
完成設定後,回到專案根目錄執行以下指令,建立整個環境:
docker compose up --build啟動成功後,造訪 http://localhost:3000 即可進入 Grafana 介面,預設登入帳號密碼為:
- Username:
admin - Password:
admin
首次登入會要求變更密碼,若僅供本地測試可跳過。
在 Grafana 中新增 Loki 資料來源
首次登入 Grafana 後,我們需要手動將 Loki 設為一個 資料來源 (Data Source),讓 Grafana 知道該從哪裡取得日誌資料。
依下列步驟操作:
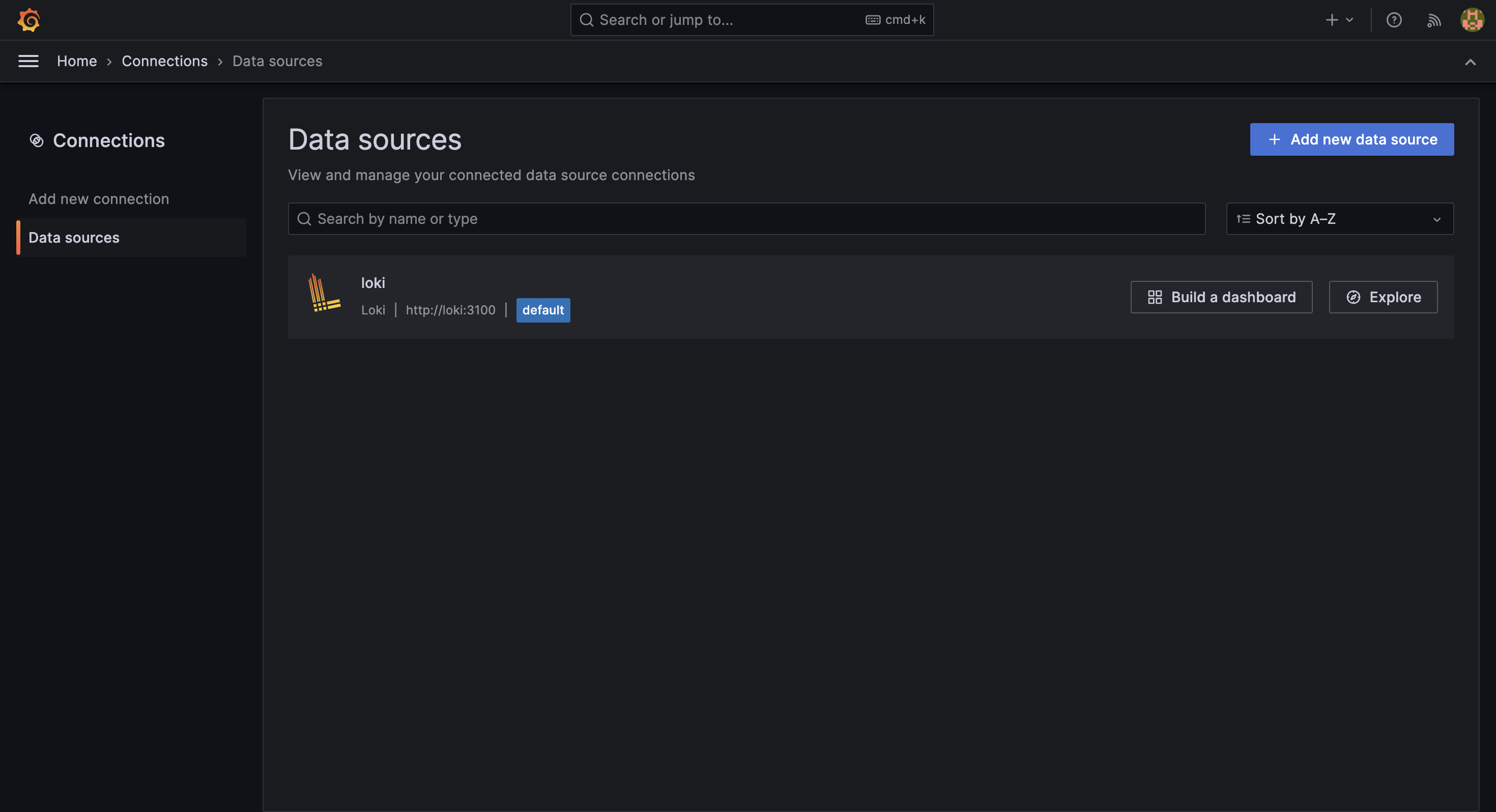
展開左側選單 ☰ (Menu) 後,選擇 Administration > Plugins and data > Plugins。或是從 Connections > Data sources 進入,效果雷同。
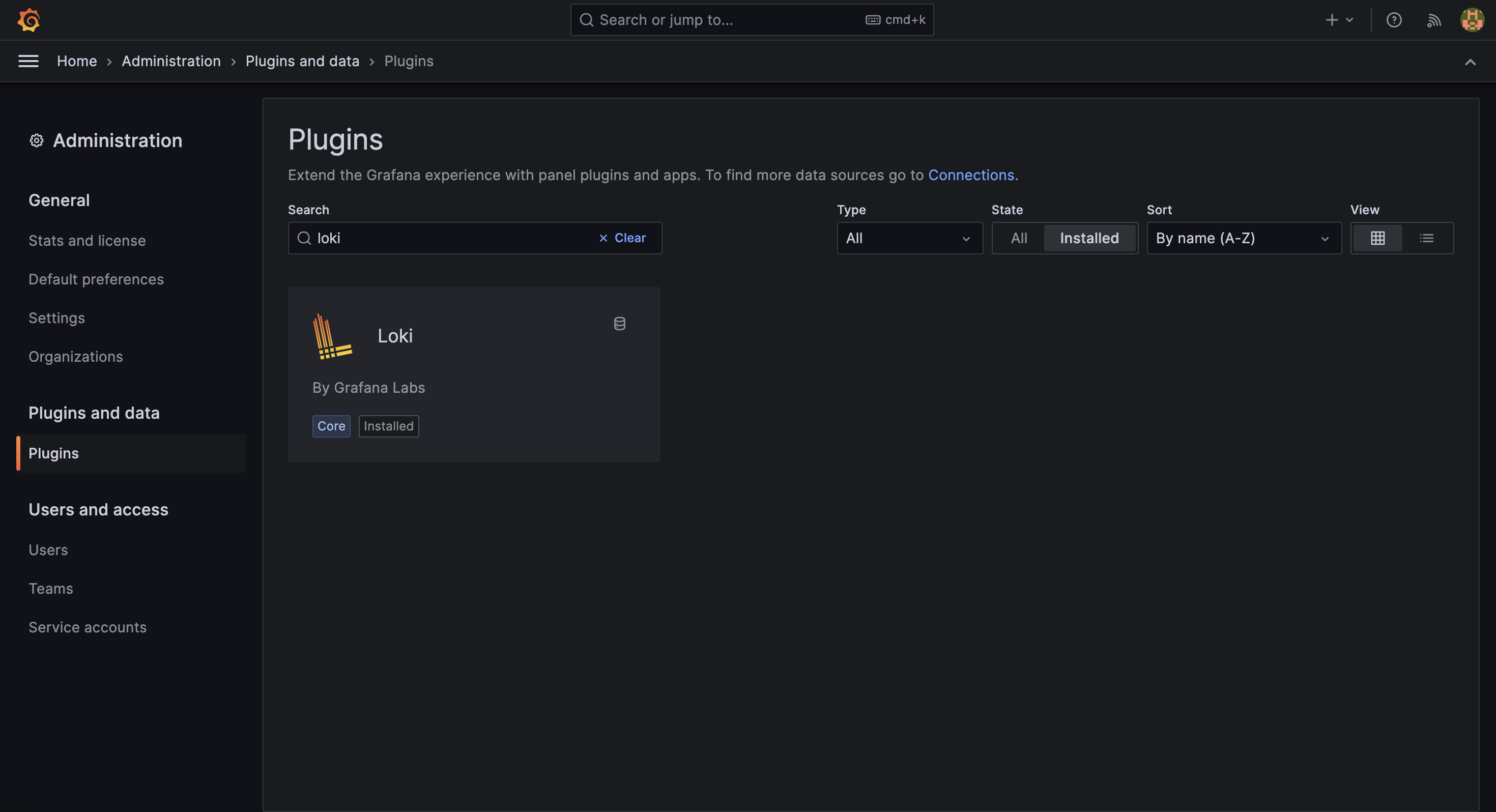
接著,搜尋 Loki,點擊進入後選擇 Add new data source 按鈕。
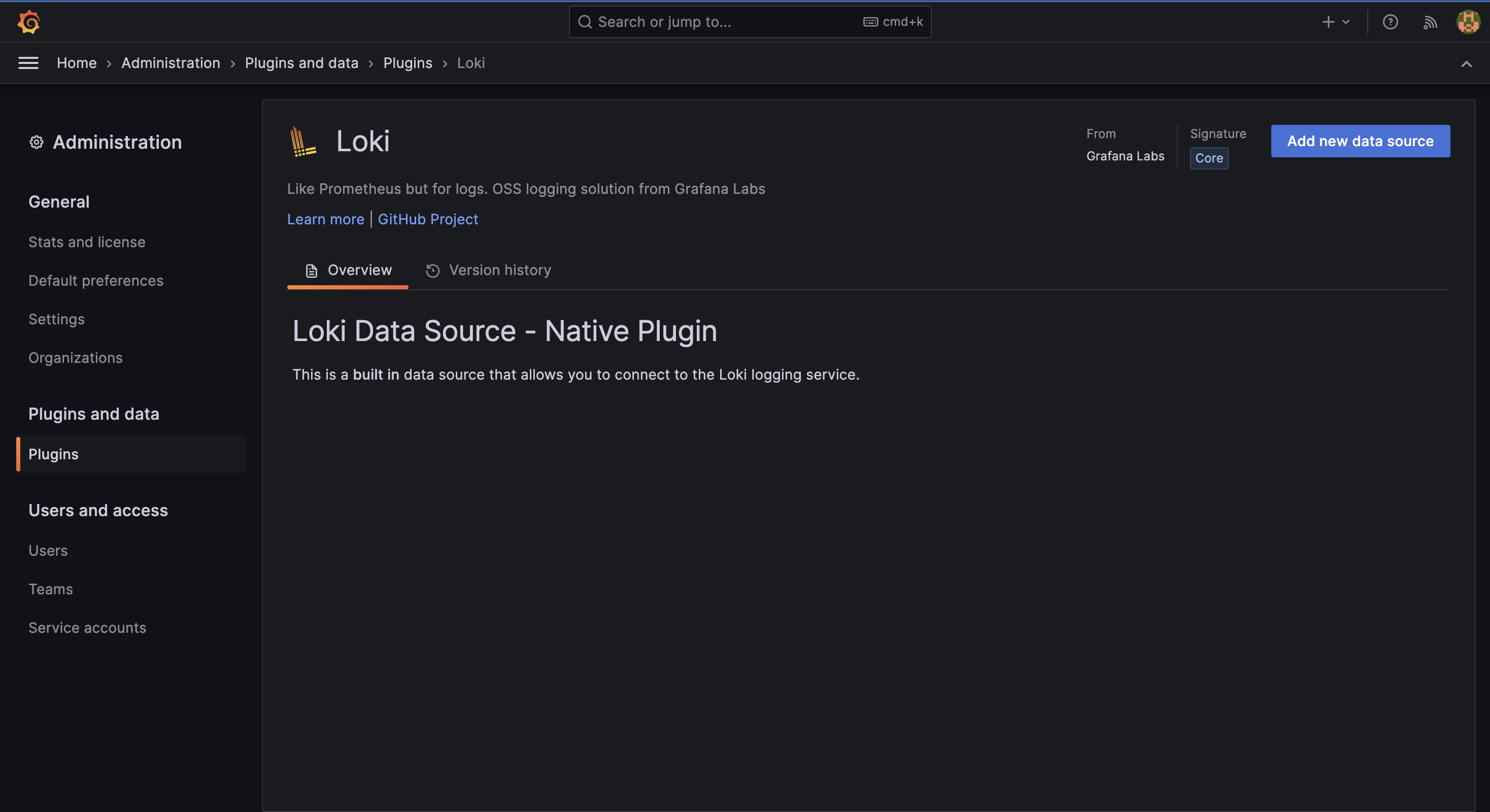
設定 Loki 的連線資訊,輸入完畢後點擊下方的 Save & test 按鈕。
建立完畢,從清單可見目前所有的資料來源。
建立 dashboard 並加入 panel
完成資料來源設定後,我們就能開始在 Grafana 中建立 dashboard,透過 LogQL 查詢與視覺化分析日誌資料。
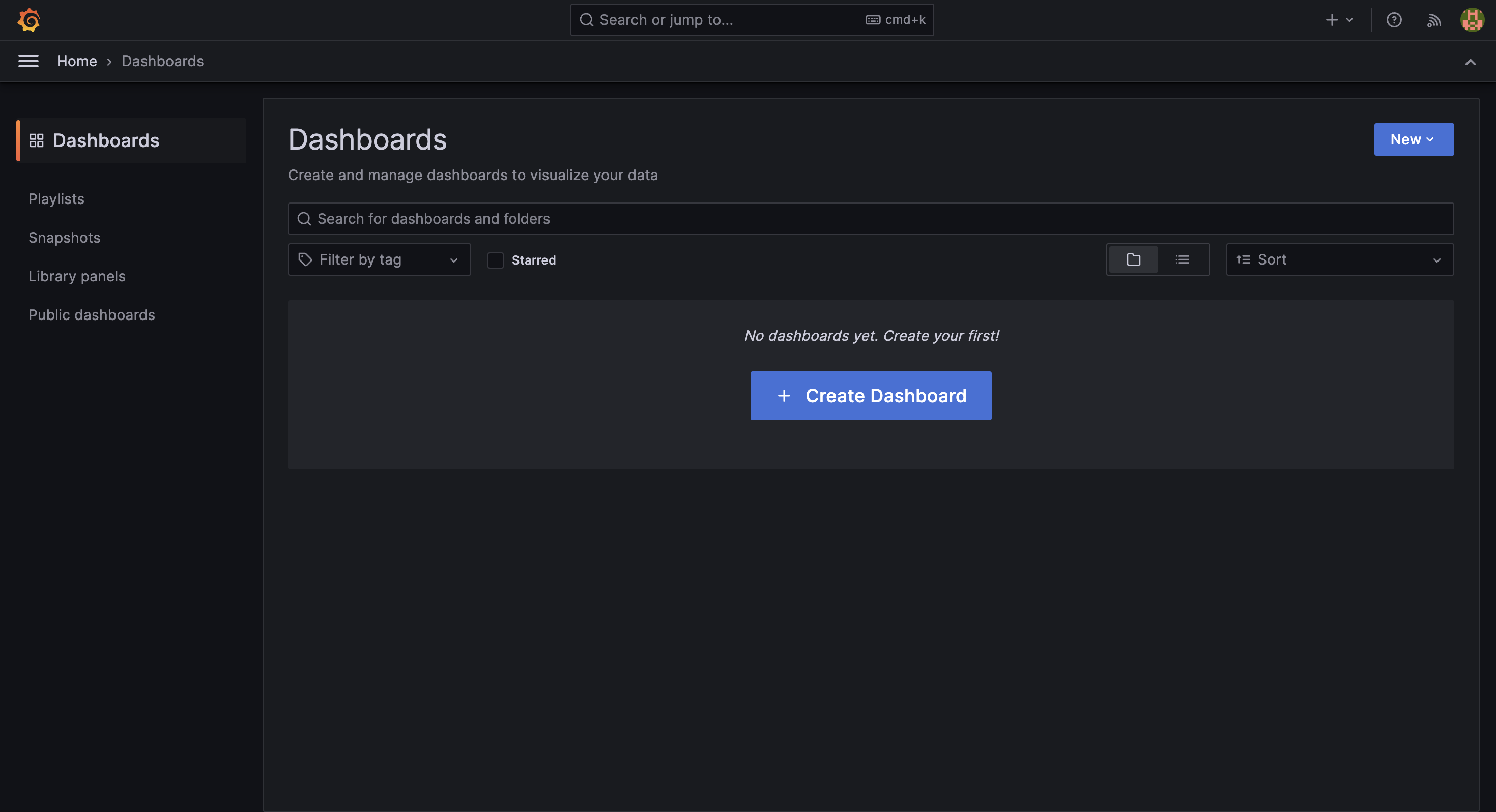
建立新的 dashboard
展開左側選單 ☰ (Menu) 後,選擇 Dashboards 並點擊 + Create Dashboard 按鈕。
進入新建立的 dashboard 後,點擊 + Add visualization 按鈕。
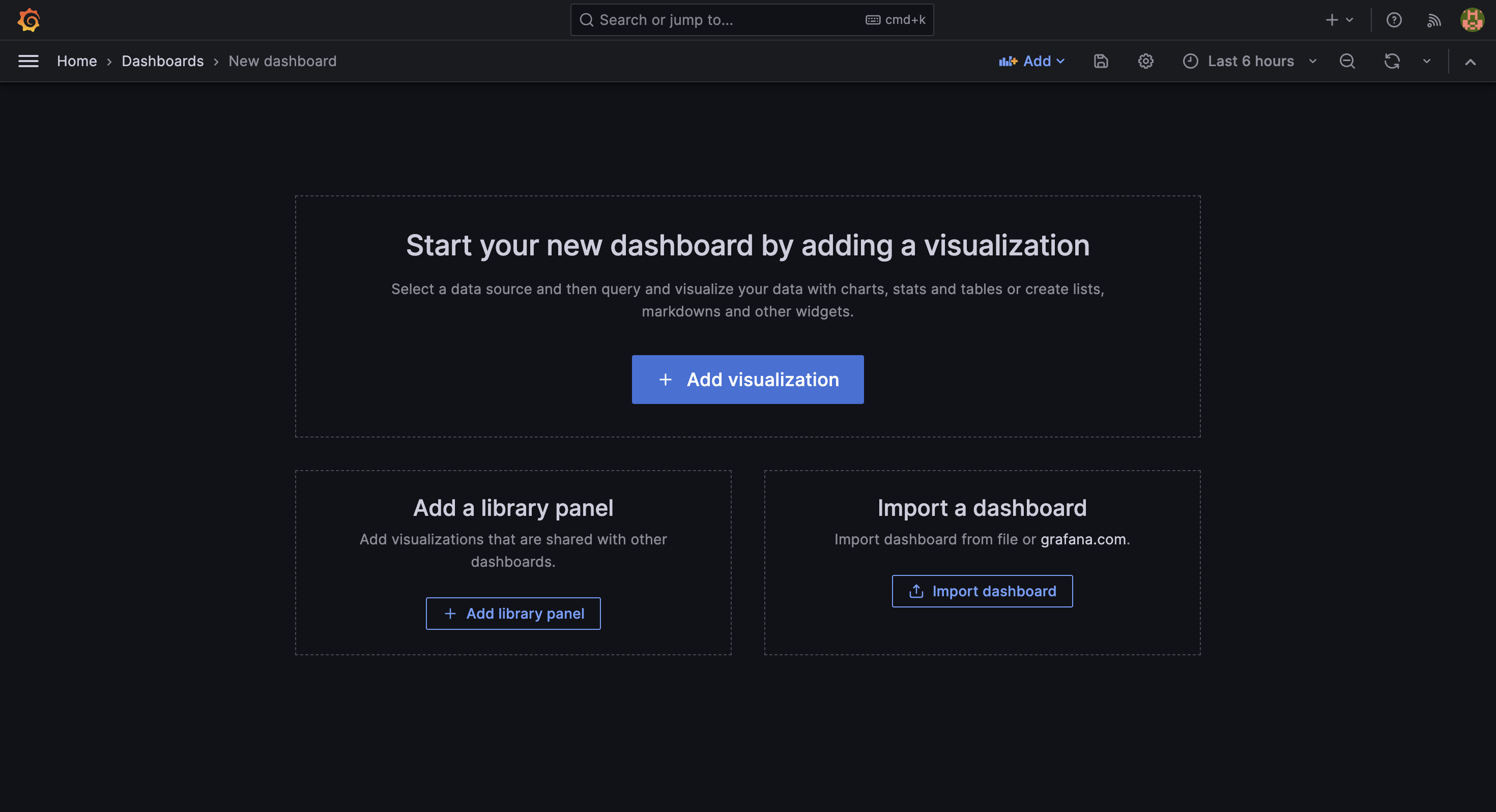
接著會需要選擇資料來源,這裡選擇剛剛新增的 Loki 資料來源。
加入 panel
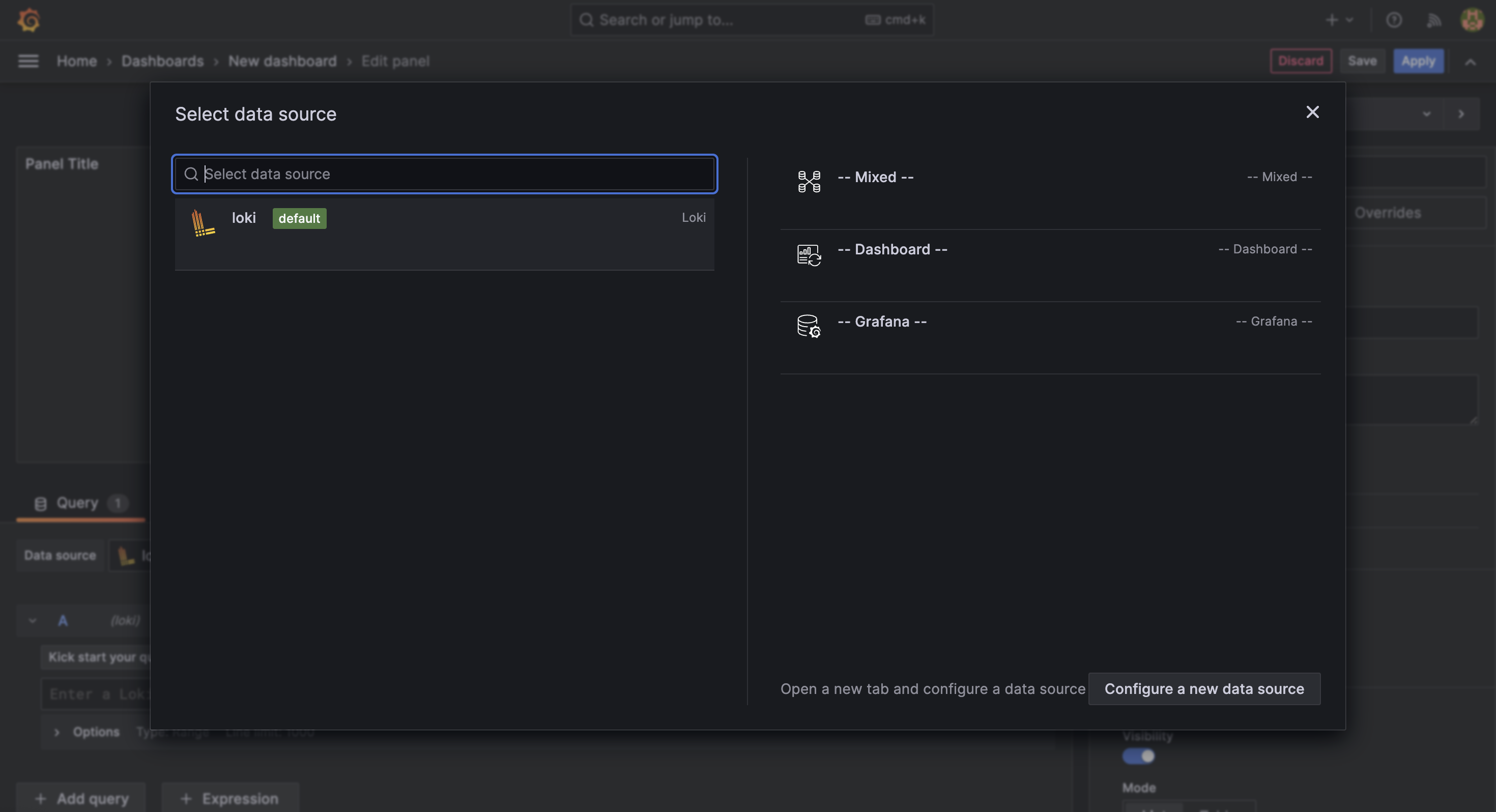
確認完畢後,會進入到編輯 面板 (panel) 的介面:
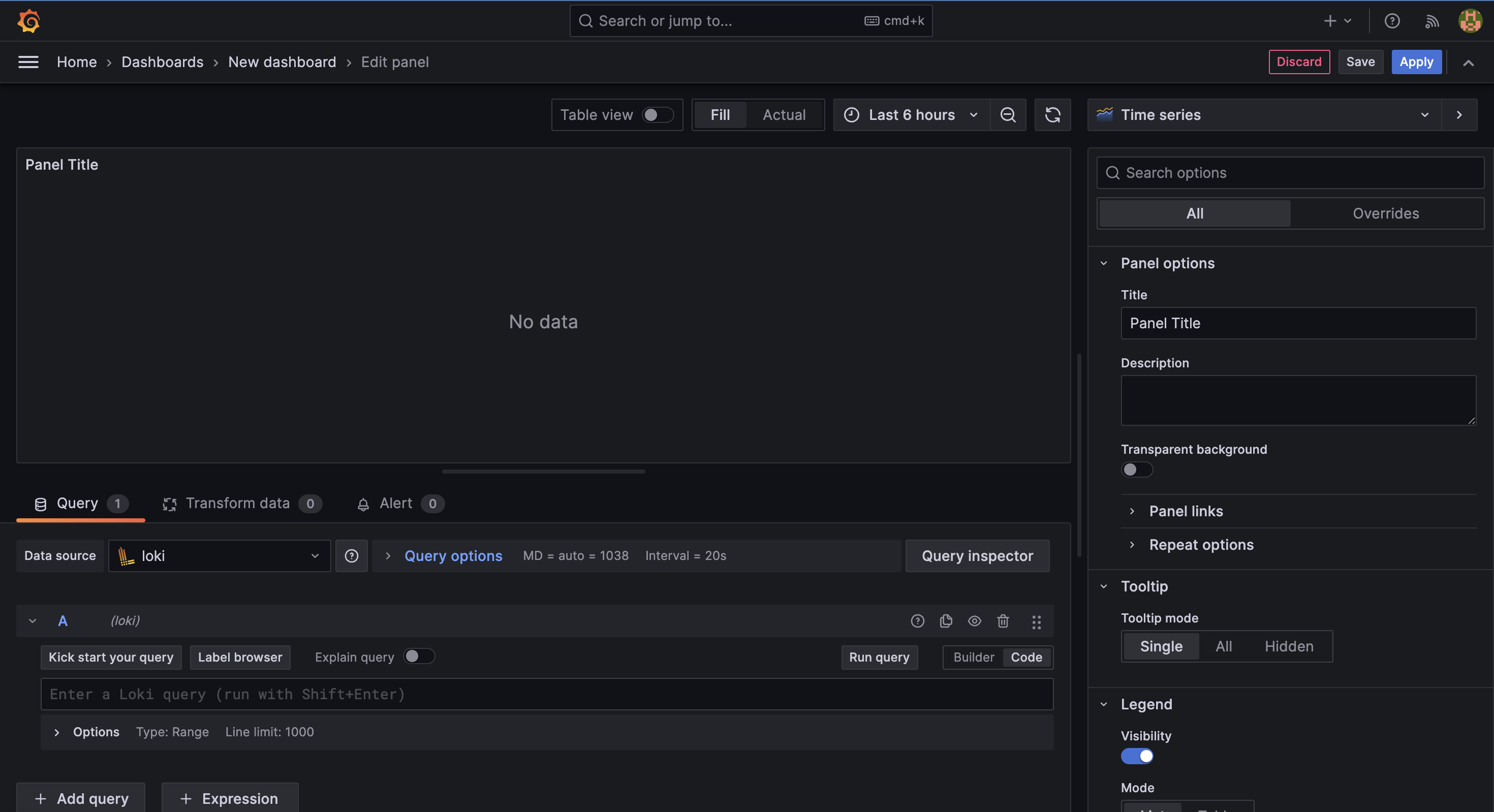
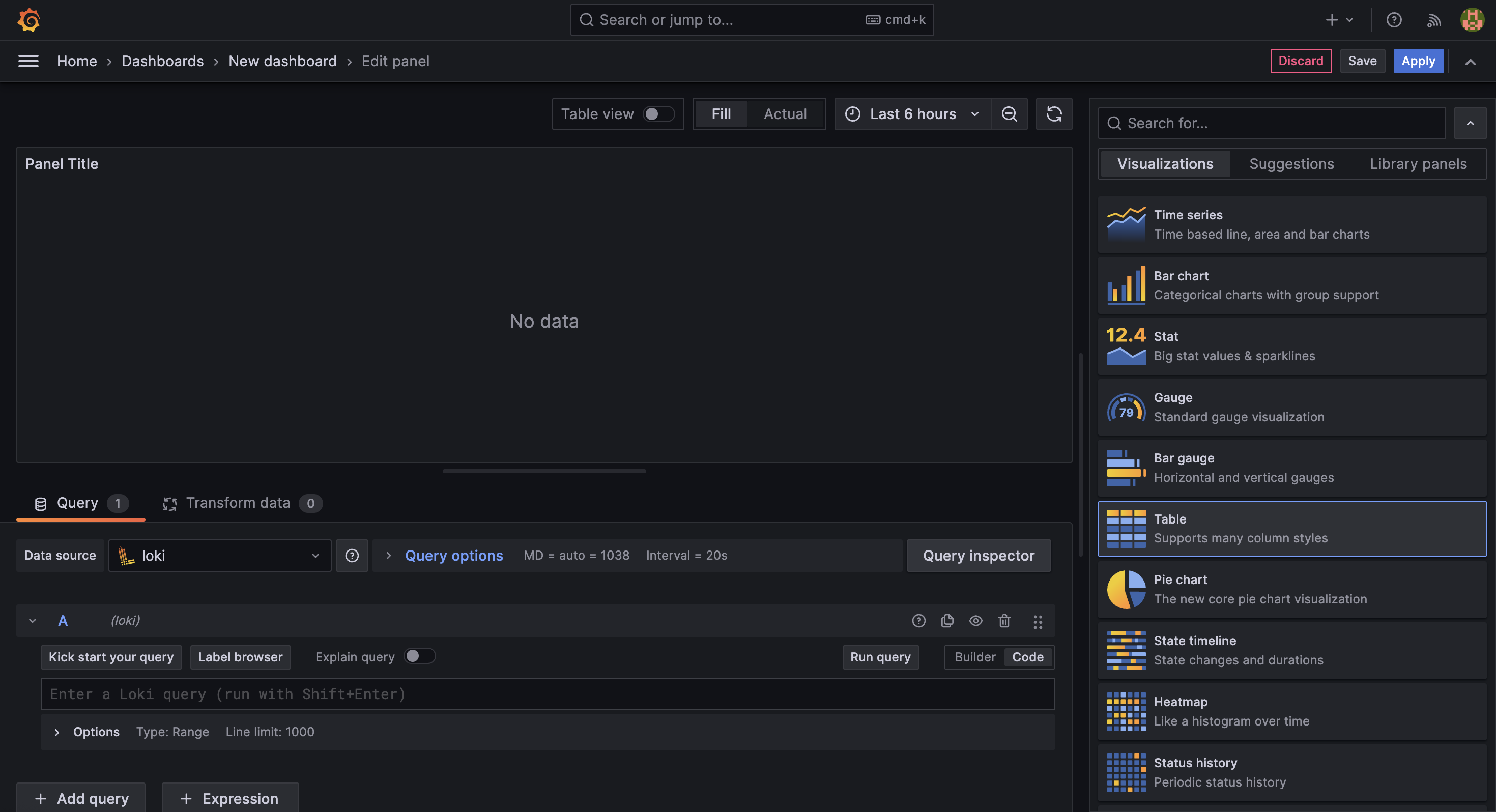
我們先在右上方的 visualization 中選擇 Table,這樣就能將日誌資料以表格的方式呈現。
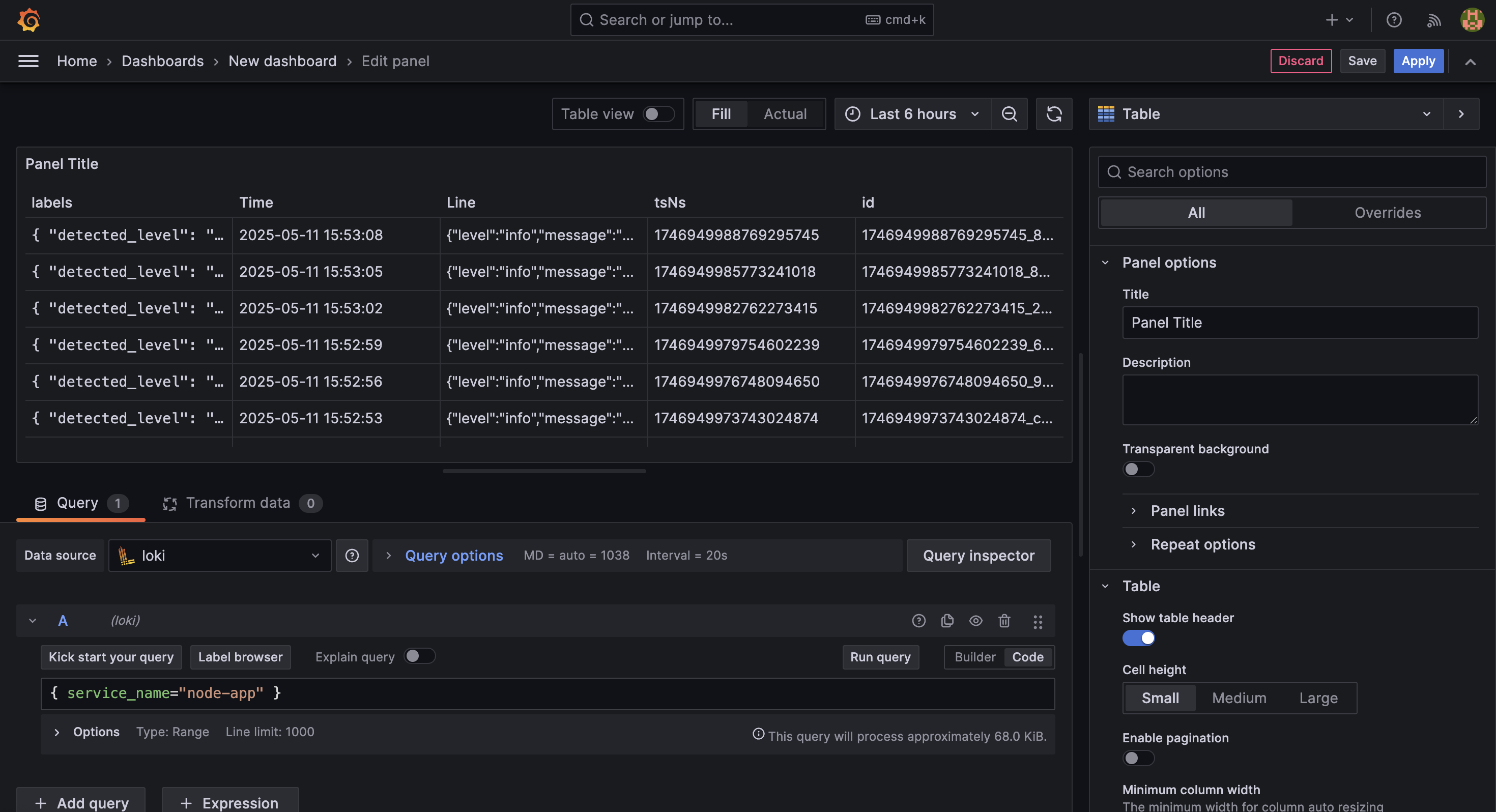
接著在下方的 Query 區域中,輸入查詢語法:
{ service_name="node-app" }並按下 Run query 按鈕,這樣就能查詢到所有來自 node-app 的日誌資料。
並在於 Line 的 column 中,可見應用程式所輸出的 stdout:
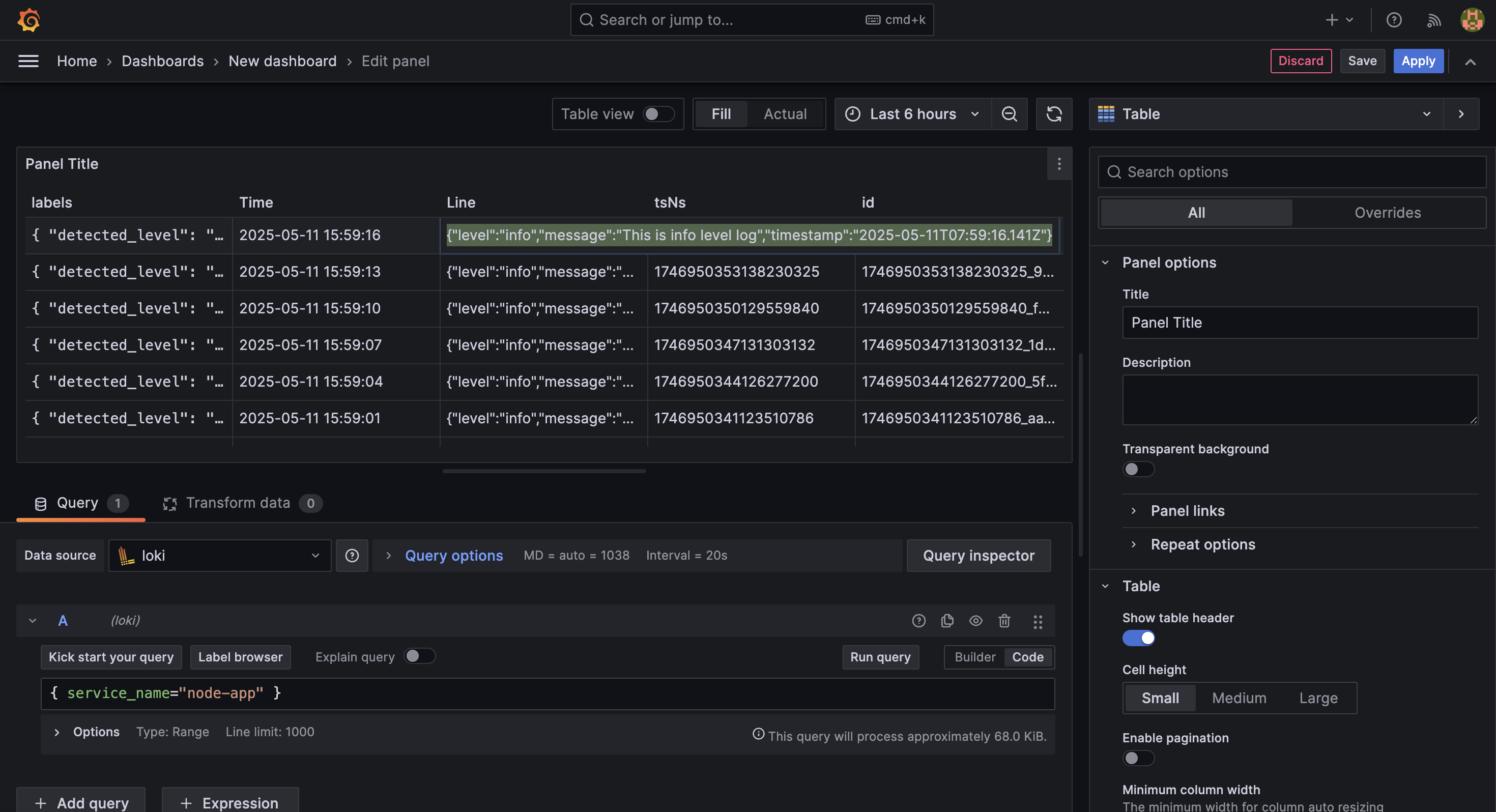
以上確認無誤,或是再進行微調後,就可以點擊右上方的 Save 按鈕,將這個 dashboard 儲存起來。
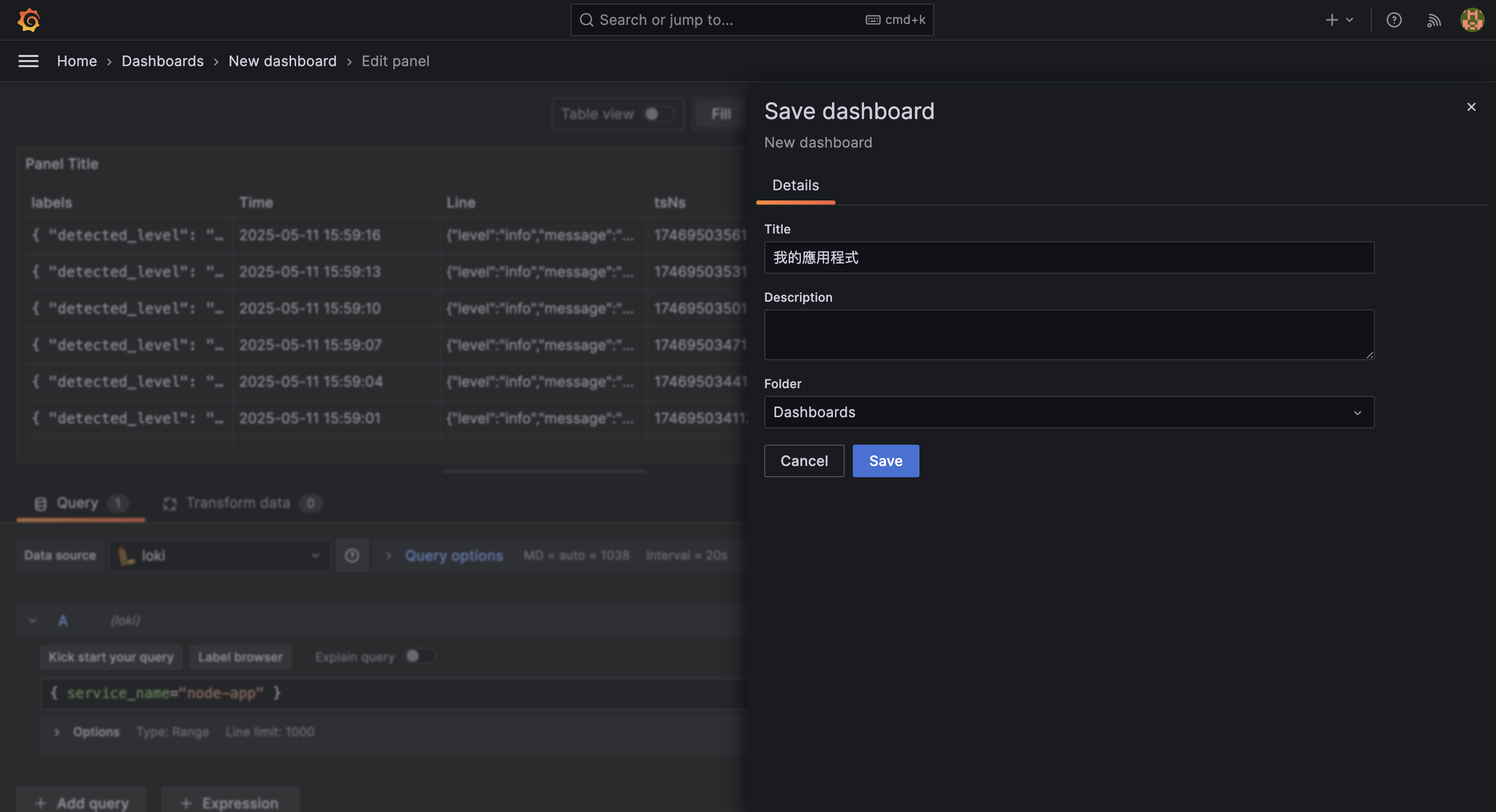
至此,我們已成功從 Grafana 建立 dashboard,並完成了第一個 LogQL 查詢的呈現。接下來,我們可以進一步將查詢轉為統計圖表,或建立告警條件來即時監控異常狀況。
撰寫 LogQL 查詢語言
在前一小節中,我們所撰寫的查詢語法叫做 LogQL,可用來針對 log 進行搜尋、過濾、統計與聚合。
LogQL 支援兩種主要查詢類型:
Log queries
Log queries 用於「查找具體的日誌行資料」,由 log stream selector 搭配 log pipeline 組成,基本語法如下:
{ log_stream_selector } | pipeline_1 | pipeline_2 ...- Log stream selector 使用
{和}所包覆,以key=value組合描述來源,可使用,串接多條件。 - Log pipeline 則是用來對查詢結果進行處理,通常會使用
|符號來串接多個 pipeline,例如:
範例如下:
{ job="analyzer" } | json | level="error" | line_format "{{.message}}"語法拆解說明:
{ job="analyzer" }: 只過濾出job為analyzer的 log| json: 將 log 解析為 JSON 格式| level="error": 過濾出level為error的 log| line_format "{{.message}}": 只顯示message欄位的內容
Metric queries
Metric queries 則是用來「擴展查詢結果,進行統計或聚合」,基本語法如下:
aggregation_function({ log_stream_selector } | pipeline_1 ... [range])例如:
count_over_time({ job="analyzer" } | json | level="error" [5m])這段語法的用意是:統計過去 5 分鐘內,來自 analyzer job 且 level=error 的 log 出現次數。
此外,metric queries 分為 log range aggregations 和 unwrapped range aggregations 兩種。
- Log range aggregations: 用來統計某段時間內的 log 數量,例如錯誤出現次數。
- Unwrapped range aggregations: 針對 log 中的欄位之數值進行平均、最大值等數據運算。
這兩者屬於進階用法,會在後續章節的實例中再進行更詳細的說明。
使用 LogQL simulator
如果手邊暫時無法搭建 Loki 環境或模擬應用程式輸出的日誌行為,可以先透過 Grafana 官方提供的 LogQL simulator 進行語法測試與練習。
它適合快速驗證語法是否正確,也能協助理解不同 log pipeline 的操作效果。
若以下 logs 資料為我們的應用程式所輸出:
{ "timestamp": "2025-01-01T12:00:00.000Z", "level": "info", "message": "Crawler started", "env": "production" }
{ "timestamp": "2025-01-01T12:00:01.000Z", "level": "info", "message": "Fetching data from URL", "url": "https://example.com/api/data" }
{ "timestamp": "2025-01-01T12:00:02.000Z", "level": "info", "message": "Received response", "statusCode": 200, "durationMs": 982 }
{ "timestamp": "2025-01-01T12:00:03.000Z", "level": "warn", "message": "Response time is high", "durationMs": 1200 }
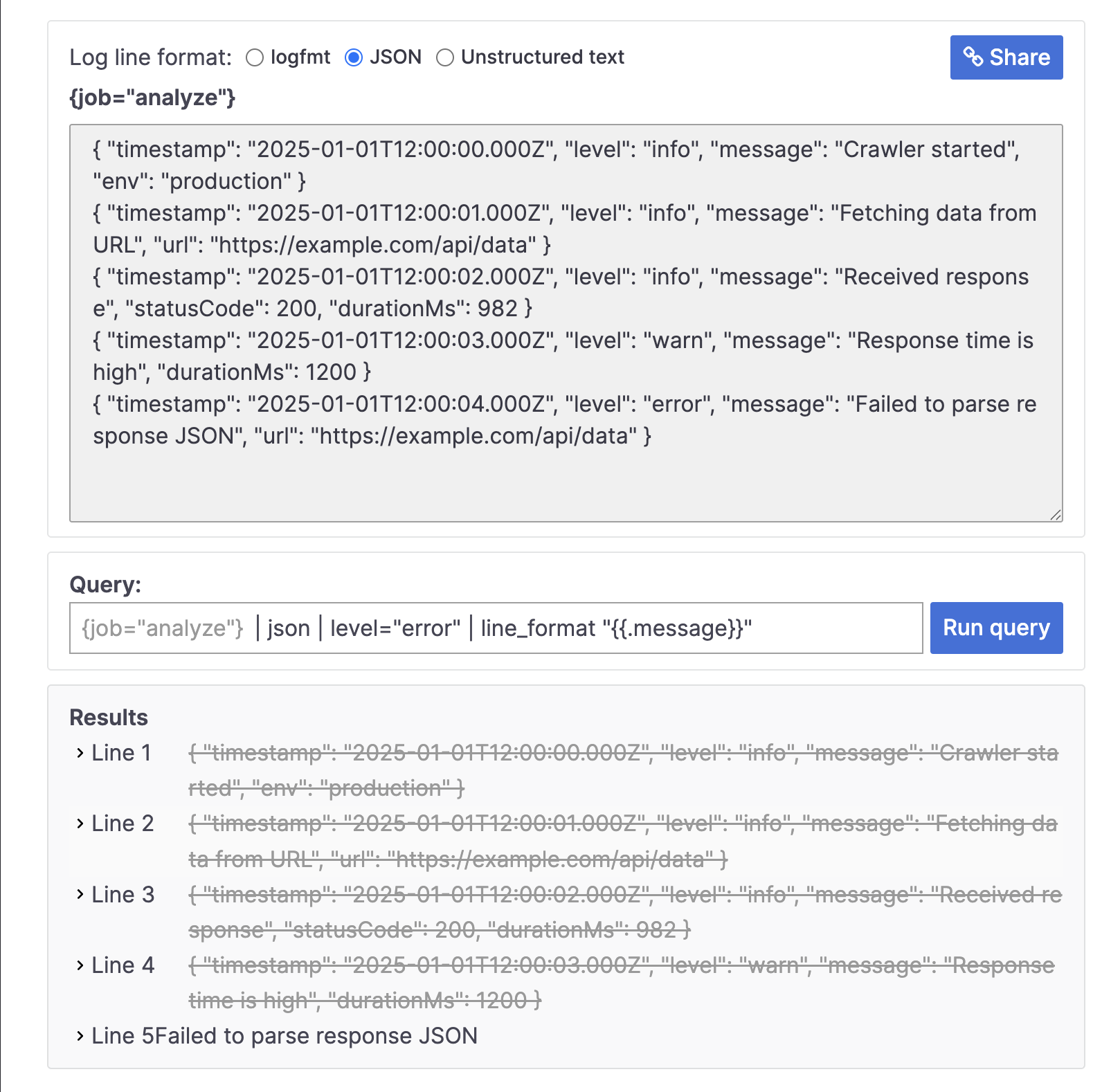
{ "timestamp": "2025-01-01T12:00:04.000Z", "level": "error", "message": "Failed to parse response JSON", "url": "https://example.com/api/data" }我們承襲上方的範例,過濾出 level 為 error 的 log,便可以使用以下 LogQL 的 log queries 語法:
{ job="analyzer" } | json | level="error" | line_format "{{.message}}"效果如下:
設定 dashboard 告警條件
除了查詢與視覺化日誌資料外,Grafana 也能根據查詢結果設定 告警條件 (Alerts),當某些異常狀況發生時 (如錯誤率過高、特定 log 出現頻繁),可以即時通知開發或維運人員,提升系統可觀測性與反應效率。
本節將以「過去 5 分鐘內 error log 數量超過閾值」為例,示範如何在現有的 dashboard panel 上建立告警條件。
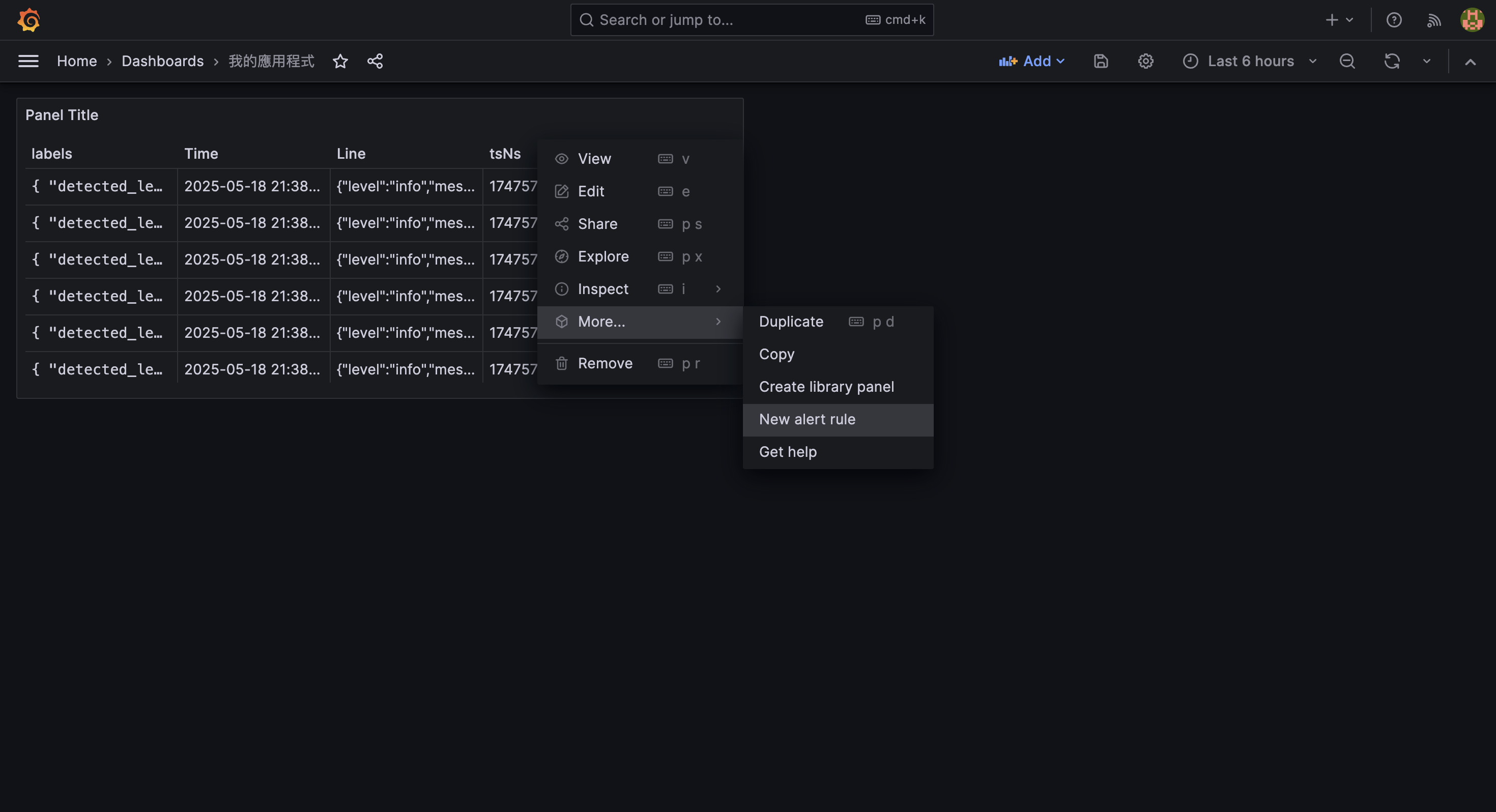
建立告警規則的步驟
在 Grafana 的 dashboard 中,選擇剛剛建立的 panel,展開右上方的選單 ⋮ (Menu),再展開 More… 選項,接著選擇 New alert rule 選項。
應用實例
最後,將介紹一些實際應用的案例,過程中會逐步引導如何設計 logs 到建立相對應的 dashboard。
確認要觀察的目標
在設計 log 結構與 dashboard 前,最重要的是先釐清「想觀察什麼」,以便針對性地記錄資料。
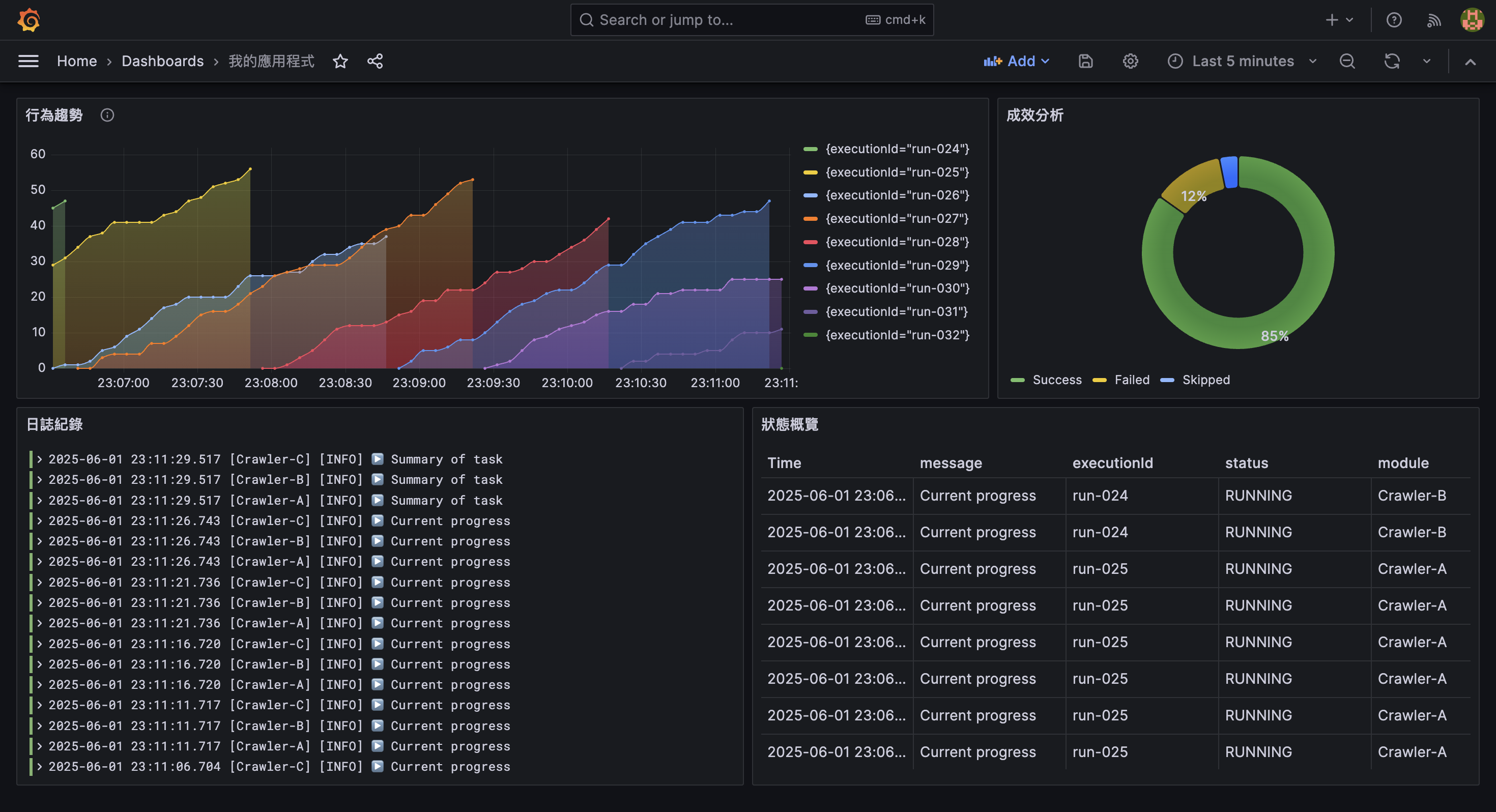
| 目標 | 典型問題範例 | 採用的 Visualization |
|---|---|---|
| 狀態概覽 | 目前有哪些任務執行中,進度如何? | Table |
| 成效分析 | 處理成功率?失敗率? | Pie Chart |
| 日誌紀錄 | 最近是否有異常?錯誤訊息為何? | Logs |
| 行為趨勢 | 某變數過去 3 小時是否有異常升高? | Time series |
預期會製作成以下的 dashboard:
狀態概覽
以下這則 log 是用來記錄任務進行狀態的範例:
{
"timestamp": "2025-05-24T01:23:45.678Z",
"level": "INFO",
"message": "Current progress",
"executionId": "run-001",
"status": "RUNNING",
"module": "Crawler-A",
"numToProcess": 1000,
"numProcessed": 420
}欄位設計說明:
executionId: 可用來追蹤每次任務的執行實例status: 目前的任務狀態 (如 RUNNING、COMPLETED)numToProcess/numProcessed: 顯示任務總數與目前已處理的數量
這些欄位可協助我們在 Grafana 中建立任務進度的 Table panel,並設定以下 Query 過濾出 Current progress 的 logs:
{ job="node-app" } | json | message="Current progress"接著 Transform data 中使用 Extract fields 的 transformation:
![]()
於 Source 中選擇 Line,將該欄位提取出來;於 Format 中選擇 Key+value pairs,將以 JSON 進行解析:
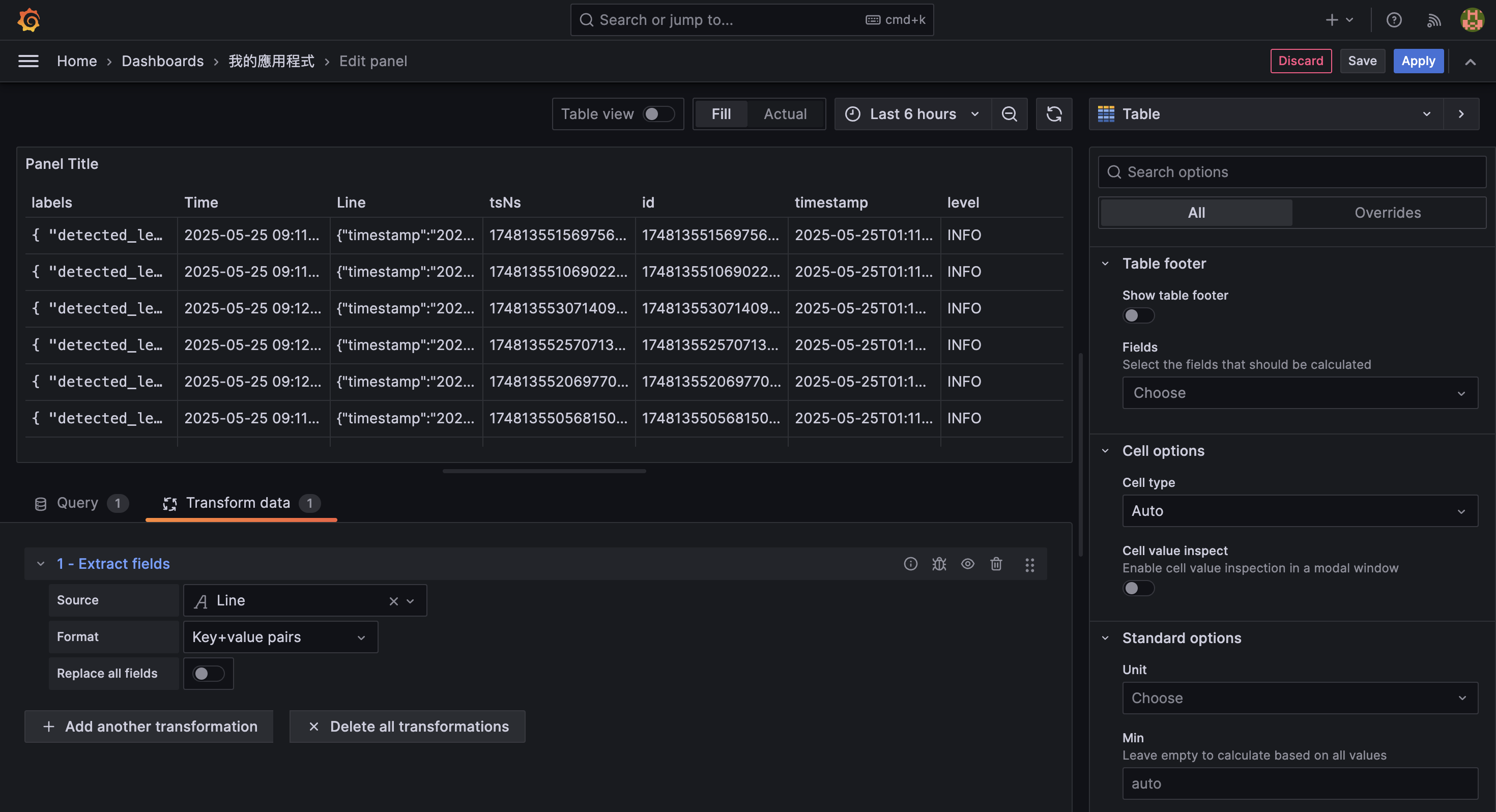
接著點選 + Add another transformation,使用 Organize fields by name 的 transformation:
![]()
並依照需求調整表格內欄位順序、顯示與否:

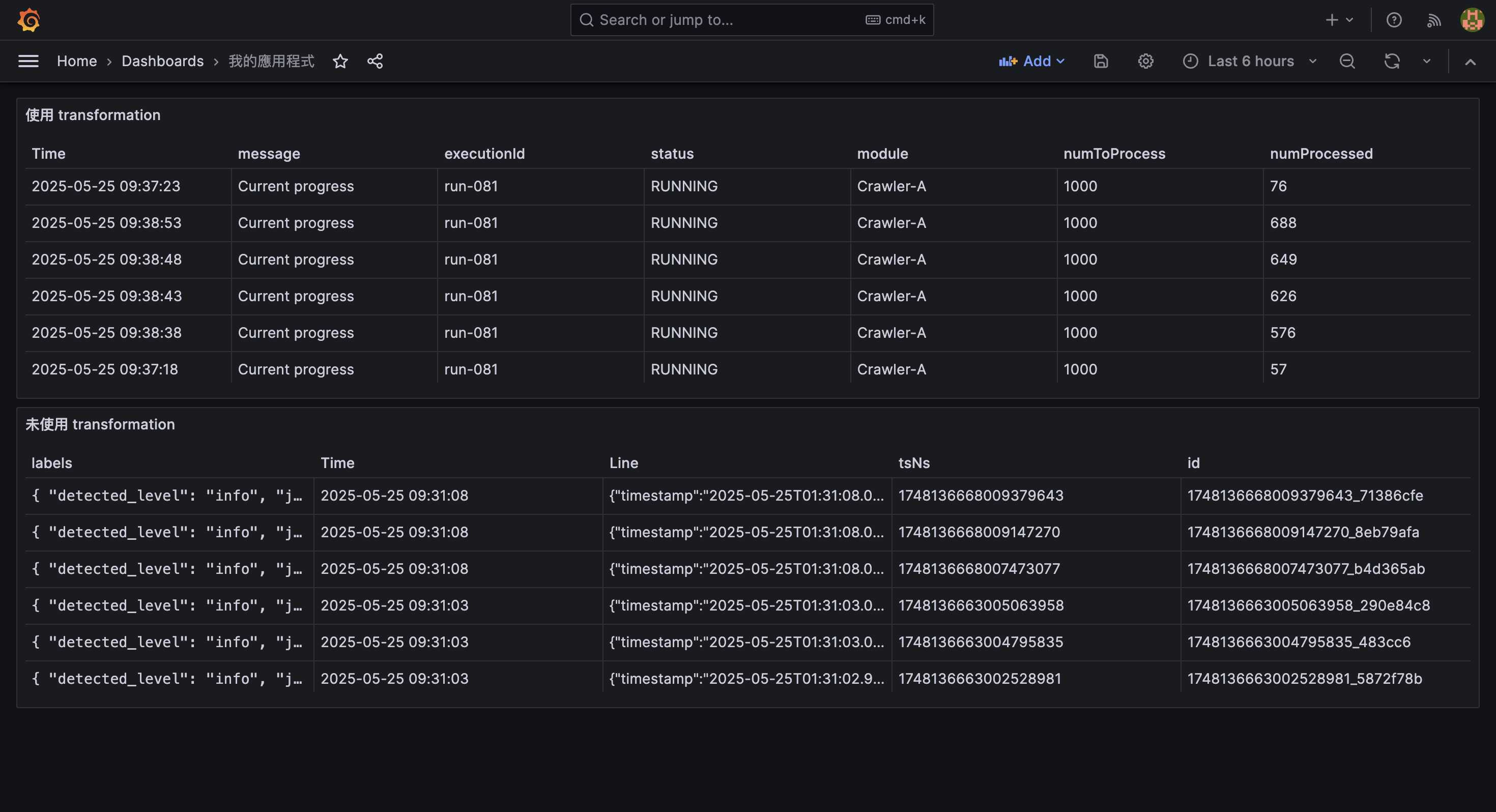
最後按下 Save 或 Apply,可以觀察到新建立的 panel 與未使用 transformation 前的差異:
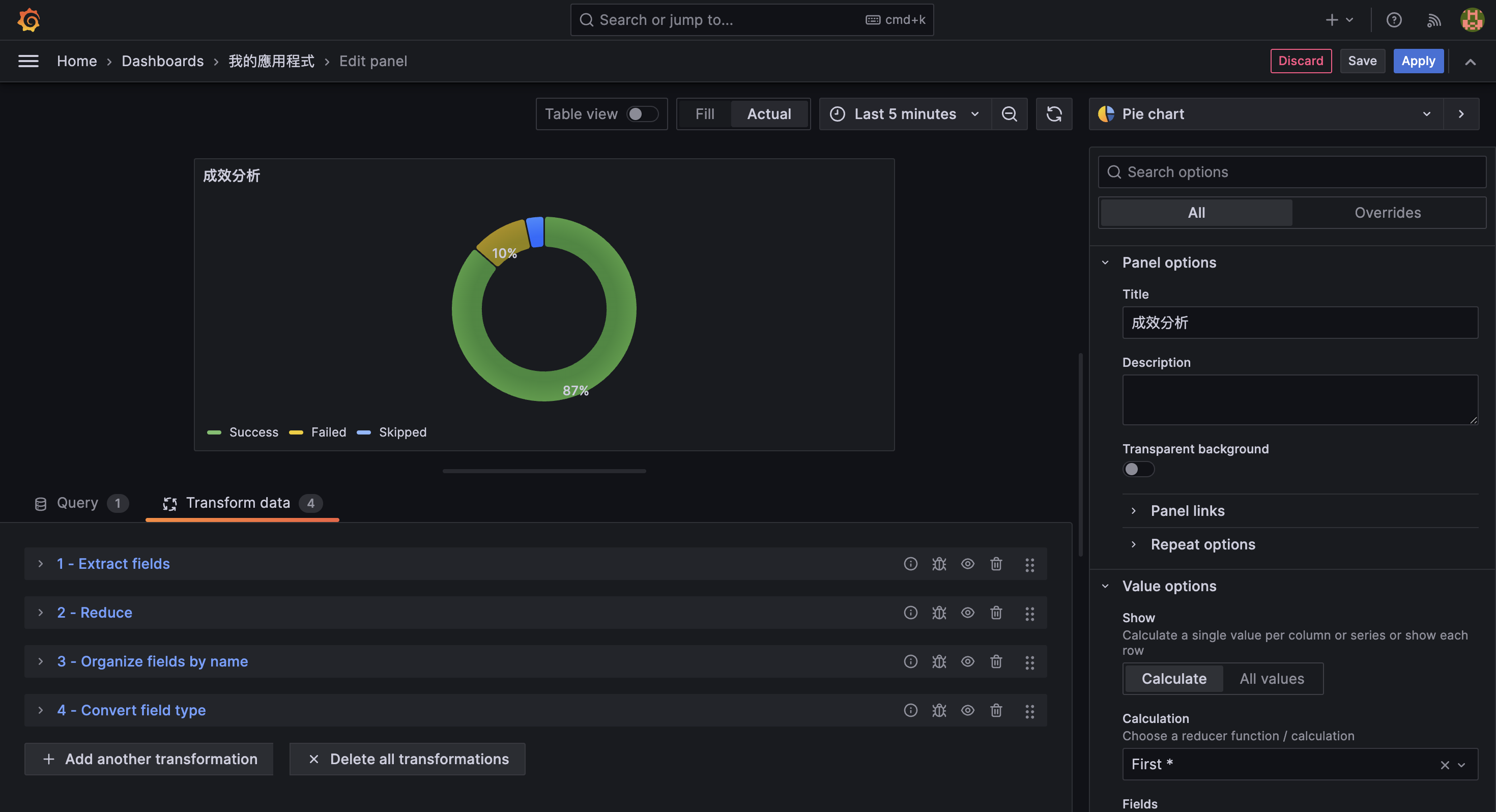
成效分析
執行結束後,我們通常會希望了解該任務的處理結果,例如:
- 成功處理幾筆?
- 有多少筆失敗?
- 是否有資料被略過?
以下這筆 log 用於記錄任務執行結尾的總結資訊:
{
"timestamp": "2025-05-24T01:23:45.678Z",
"level": "INFO",
"message": "Summary of task",
"executionId": "run-001",
"module": "Crawler-A",
"numToProcess": 1000,
"numProcessed": 1000,
"numFailed": 50,
"numSkipped": 10
}欄位設計說明:
numToProcess: 任務總筆數numProcessed/numFailed/numSkipped: 分別對應成功、失敗、略過的資料筆數
這些欄位可協助我們在 Grafana 中建立任務進度的 Pie Chart panel,視覺化顯示處理結果的比例分佈。
在 Query 區塊輸入以下語法,過濾出 Summary of task 類型的 logs:
{ job="node-app" } | json | message="Summary of task"並在 Visualization 中選擇 Pie chart,接著在 Field 中選擇 numProcessed、numFailed 與 numSkipped 欄位:
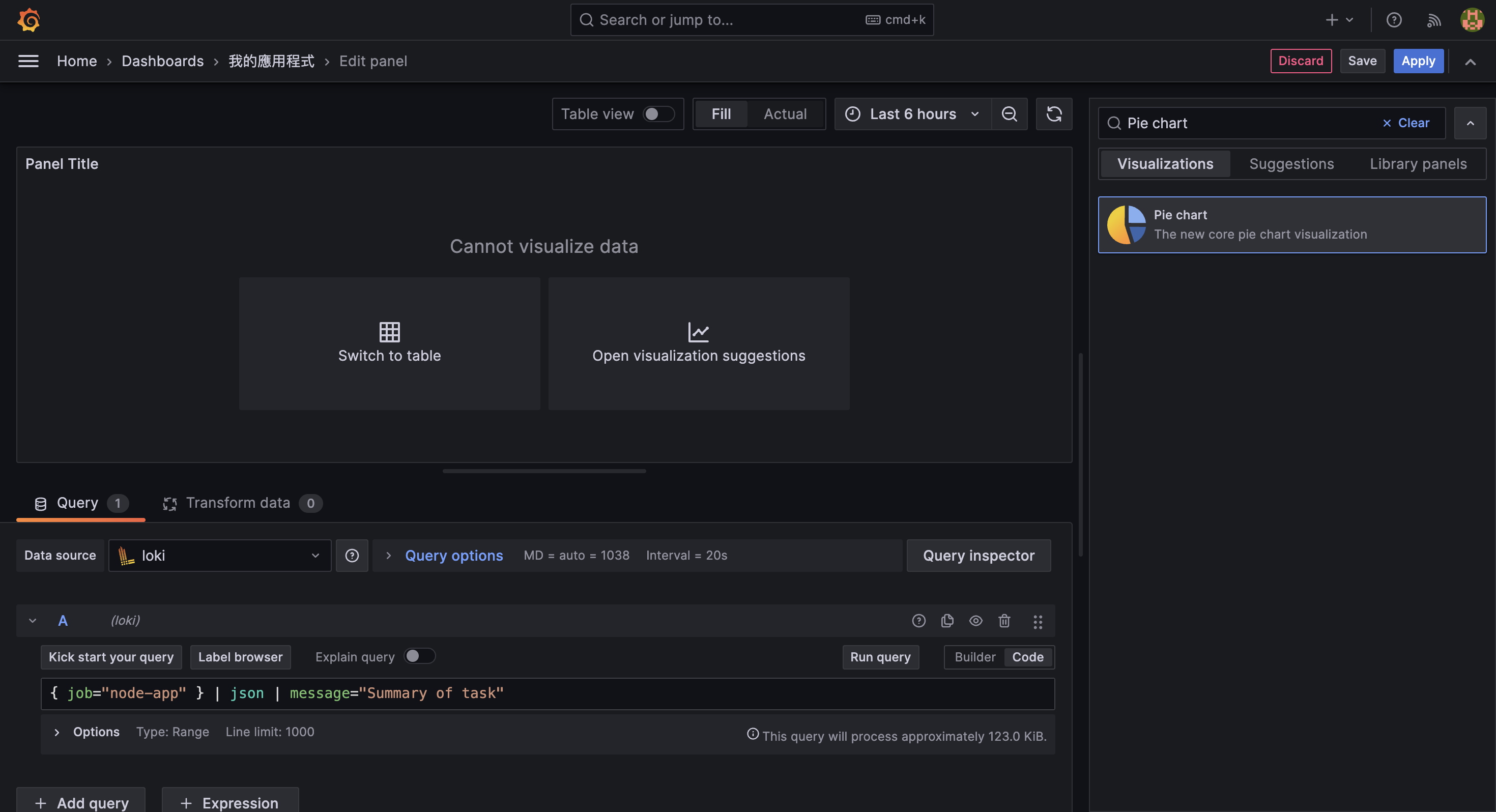
為了讓要資料能夠被 Pie chart 正確解析,在 Transform data 中依序使用以下四種 transformations:
- Extract fields: 將
numProcessed、numFailed與numSkipped欄位提取出來- Source 選擇 Line
- Format 選擇 Key+value pairs
- 勾選 Replace all fields
- Reduce fields: 只需要最新的一筆資料
- Mode 選擇 Reduce fields
- Calculations 選擇 First * 或 First
- Organize fields by name: 將欄位調整為視覺化時使用的標籤名稱
- 將
numProcessed更名為Success - 將
numFailed更名為Failed - 將
numSkipped更名為Skipped
- 將
- Convert field type: 將欄位轉換為數值型別,才能夠被 Pie chart 正確解析
- 將
Processed、Failed與Skipped欄位轉換為 Number
- 將
過程中,可開啟 Table view 模式觀察 transformation 的效果是否合乎期待:
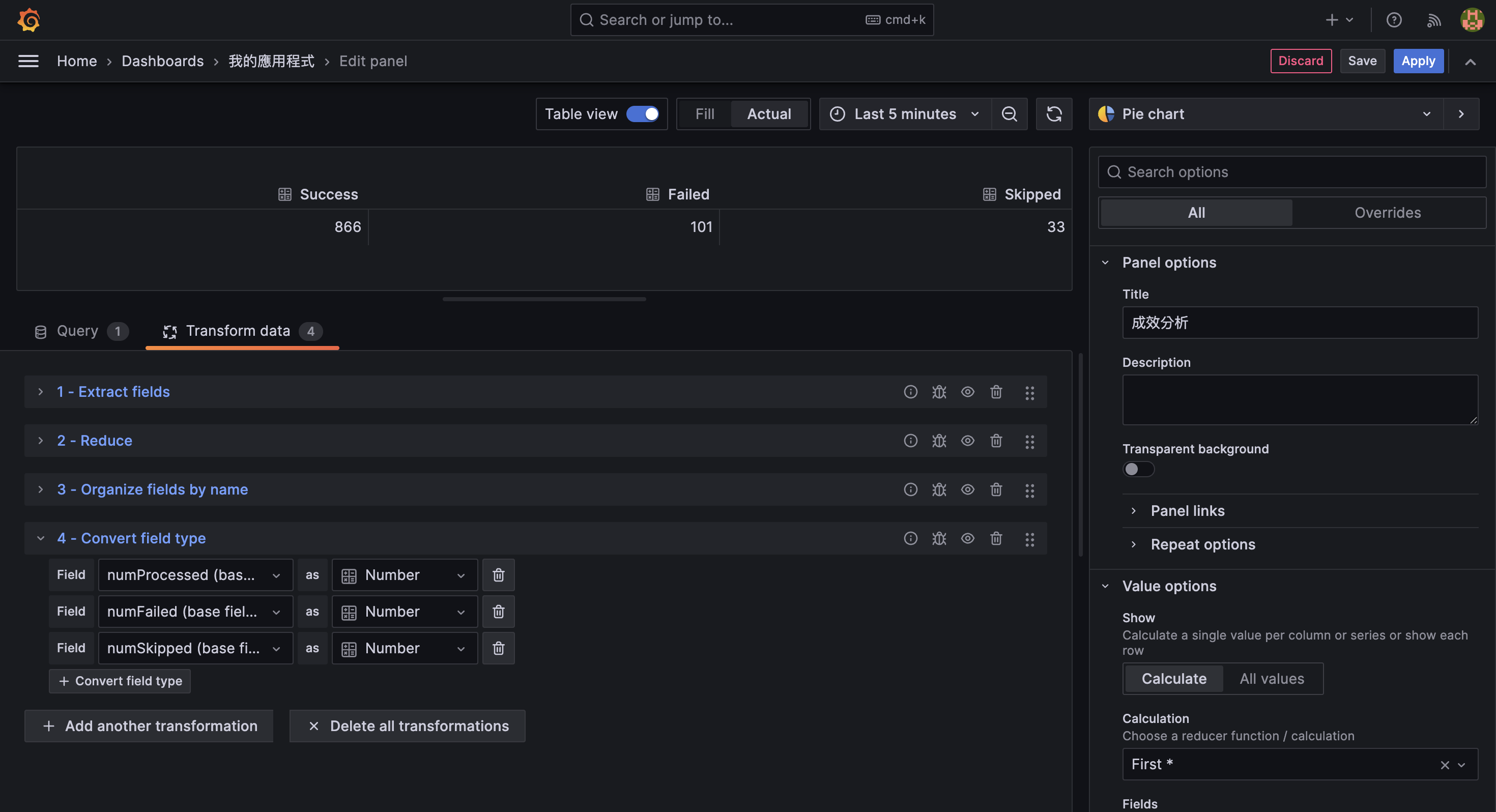
確認資料設定符合預期後,可以再將其關閉。
接著在 Visualization 中調整 Pie chart 的樣式與顯示方式:
- Piechart type: 設定為 Donut
- Labels: 設定為 Percent
即會呈現如下結果:
日誌紀錄
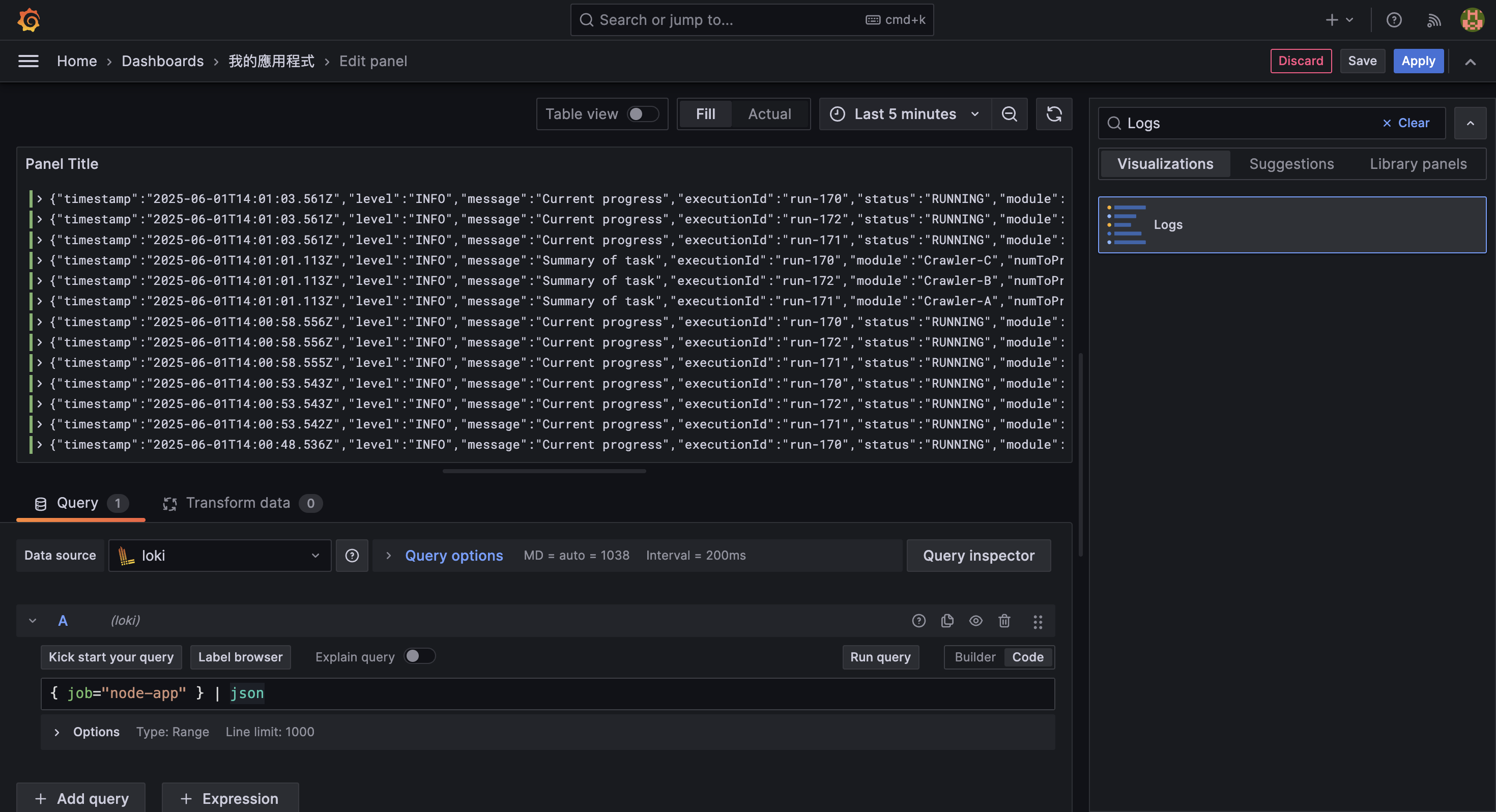
除了透過統計與圖表來掌握任務概況,我們有時也需要直接查看原始日誌內容,以協助下數幾種情境:
- 確認錯誤訊息的細節與上下文
- 排查非預期的行為或資料問題
- 驗證系統是否如預期執行流程
為了查看所有 log 訊息 (包含 INFO、ERROR 等層級),我們可以沿用前面範例所產生的 logs,在 Query 區塊輸入以下語法,完整接收所有輸出:
{ job="node-app" } | json並在 Visualization 中選擇 Logs,這樣就能直接查看所有來自 node-app 的日誌行為。
然而,呈現的資料格式不夠直觀,我們可以使用 line_format 來調整日誌的顯示格式,使其更易讀。
{ job="node-app" } | json | line_format "[{{.module}}] [{{.level}}] ▶️ {{.message}}"這段設定會將原始 log 轉為類似這樣的格式:
[Crawler-A] [INFO] ▶️ Current progress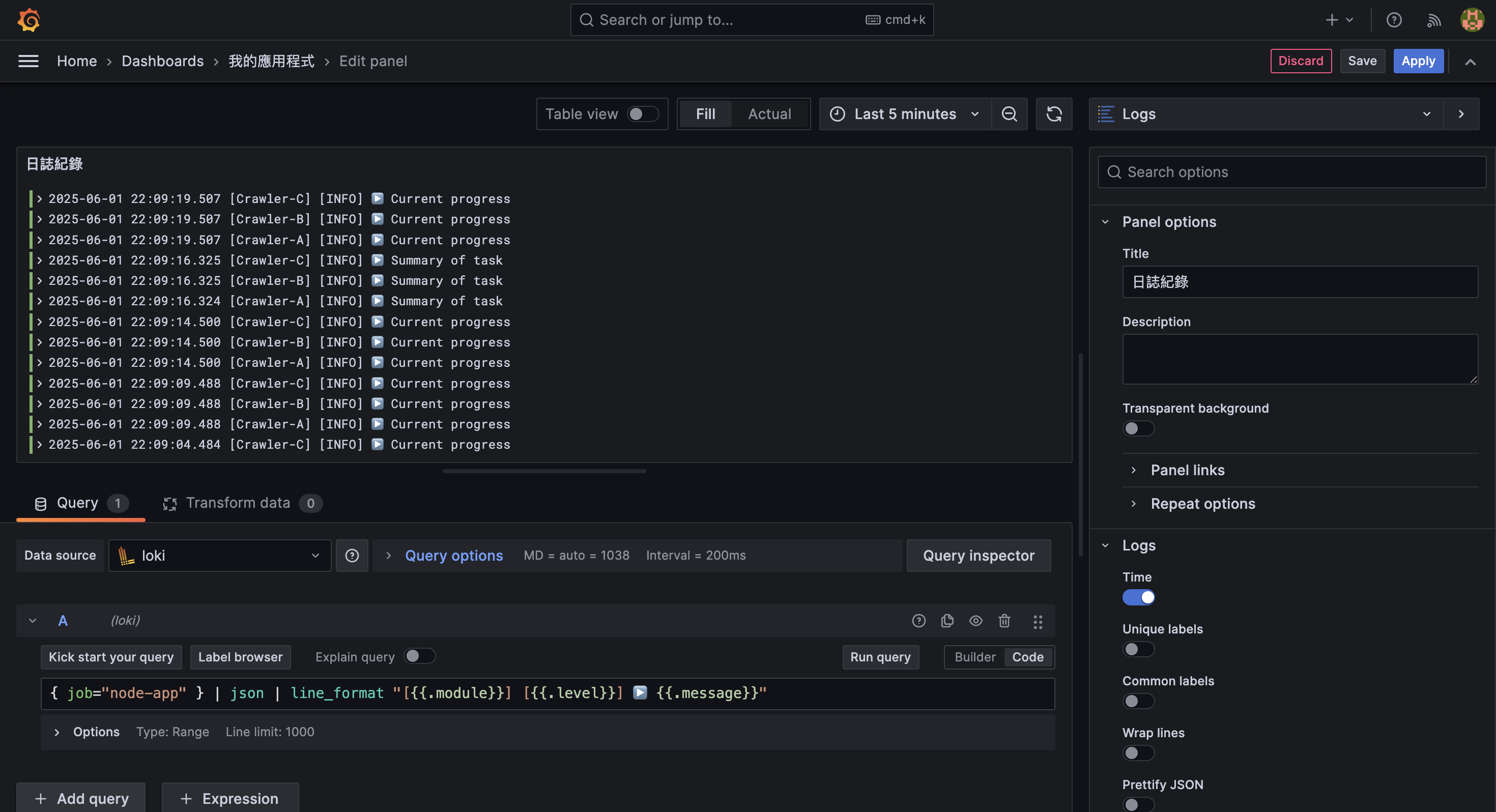
行為趨勢
除了統計每次任務的總結結果,我們有時也希望觀察某些「變數在時間上的變化趨勢」,以便找出異常升高或某段時間異常高頻率的狀況。
舉例來說,我們可能會希望知道:
- 哪段時間
numFailed明顯上升? - 哪些模組在某個時段特別不穩定?
這類觀察非常適合使用 unwrap 搭配 max_over_time 函數,將 log 中的欄位拉出來轉為 time series 數據,進而畫出時間趨勢圖。
max_over_time(
{ job="node-app" }
| json
| message="Current progress"
| unwrap numFailed
[$__interval]
) by (executionId)unwrap numFailed: 從 log 中取出numFailed欄位作為數值max_over_time(...): 在每個時間區段中取最大值,其中$__interval會自動根據 dashboard 的時間範圍調整by (module): 依照 module label 分組,讓每個模組產生一條獨立的 time series
在 Visualization 中選擇 Time series,搭配 Table view 檢視檢視得知,各時間點的 numFailed 數值已被正確提取出來。
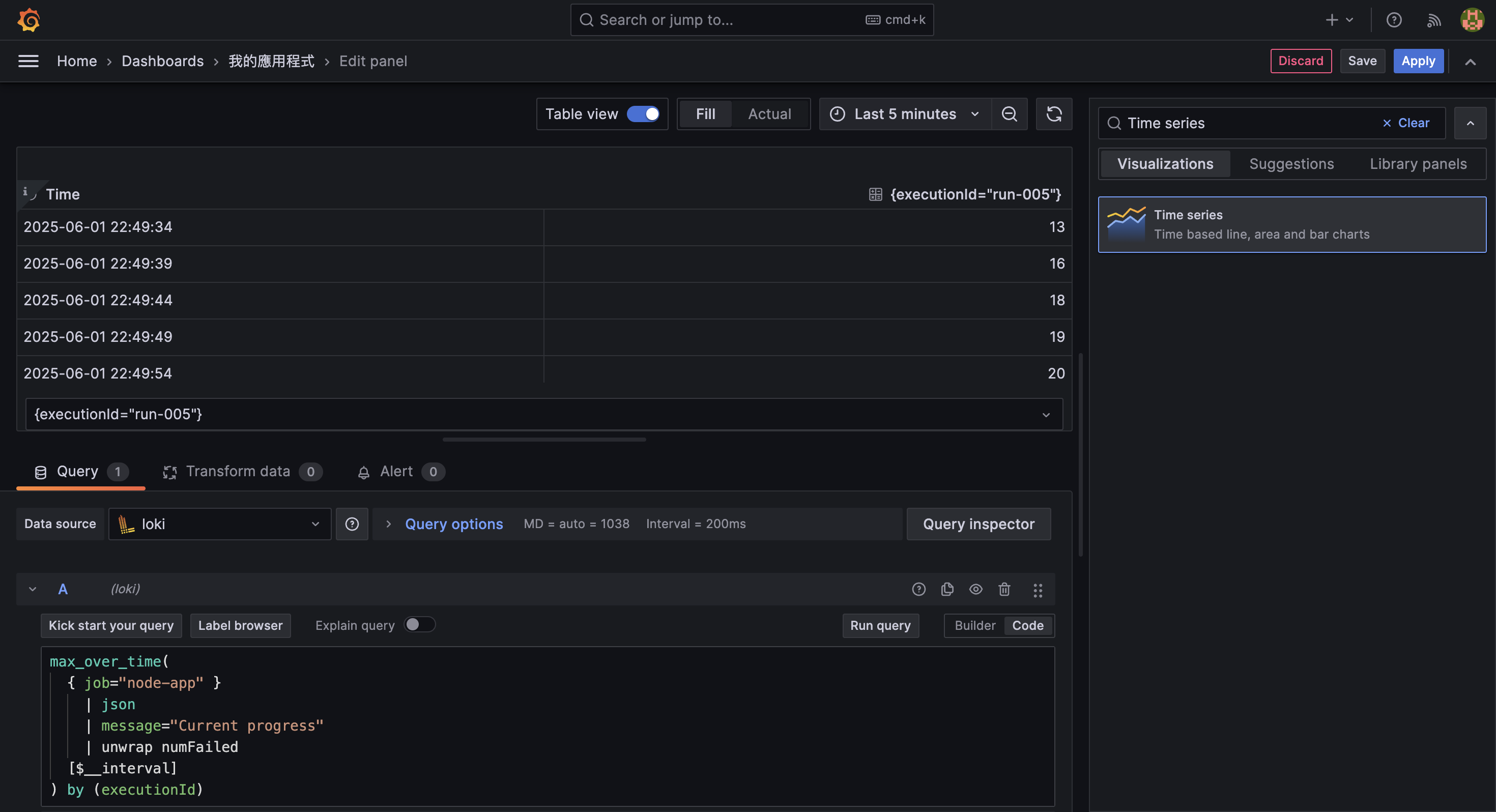
由於先前已在 Query 中使用了 by (executionId),因此每個 executionId 都會有一條獨立的線條,這樣就能清楚看到每次任務的失敗數量隨時間的變化。
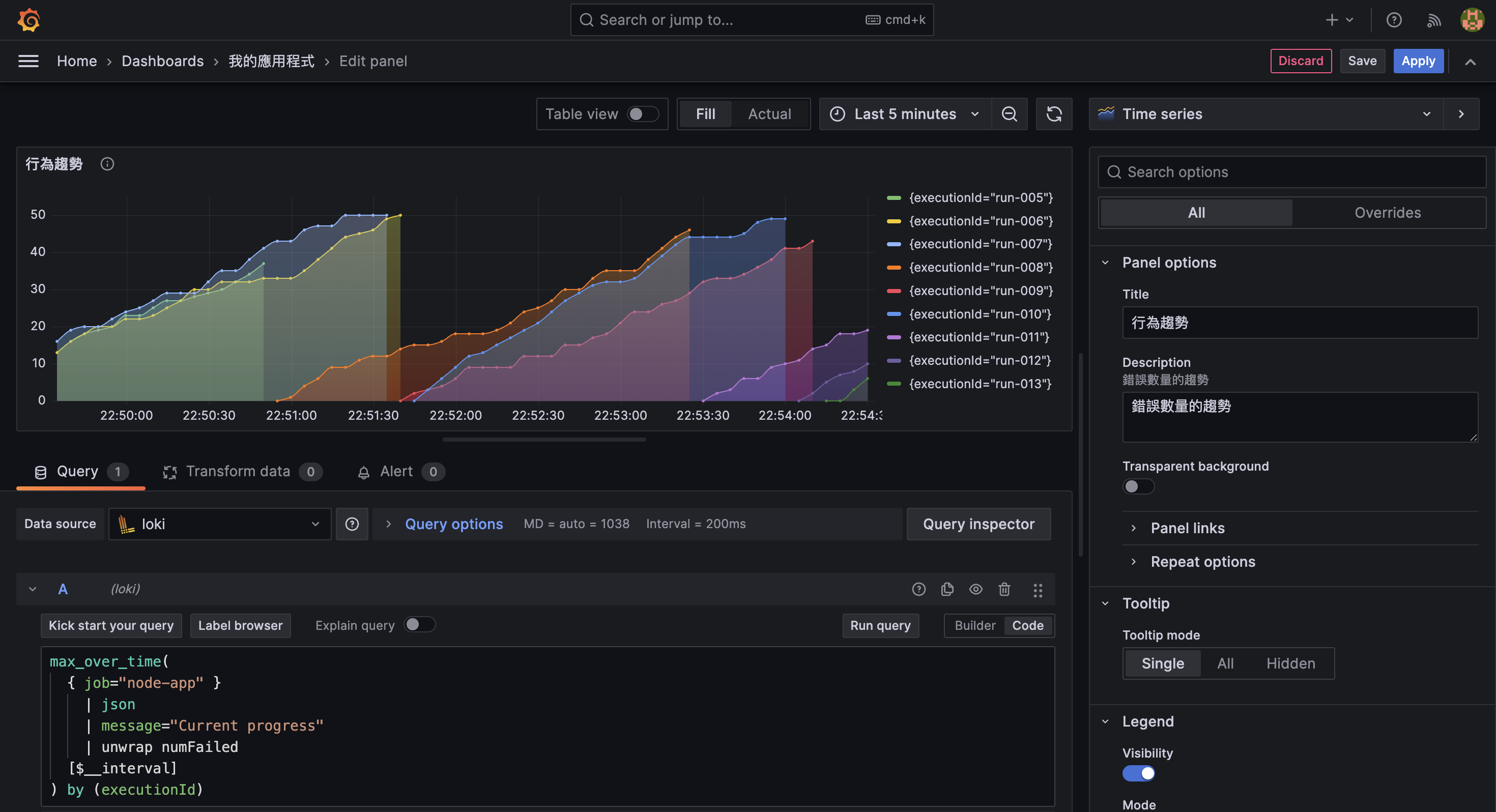
從上圖可以看出,某些任務在特定時間點的 numFailed 明顯上升,進而可以對系統現況進行更深入的分析。
範例程式下載
完整範例 source code: wazho/grafana-loki-practice
範例程式中,包含了 config 資料夾與 Node.js 應用程式的 Dockerfile 等,可以使用以下指令來建立範例的測試環境:
# 下載範例專案
git clone git@github.com:wazho/grafana-loki-practice.git
# 進入專案資料夾
cd grafana-loki-practice
# 建立 docker-compose 環境
docker-compose up -d